
注意力马达:让推荐模型"看"到你的兴趣焦点
如果说 Embedding 是推荐系统学会理解世界的"文字",那么 注意力机制(Attention Mechanism) 就是教会模型如何"阅读理解"的老师。它让模型在处理海量信息时,能够像人一样抓住重点,动态地聚焦于当前任务最相关的信息,从而做出更精准的判断。
在注意力机制被引入之前,模型处理用户的历史行为序列时,通常采用一种简单粗暴的方式:池化(Pooling)。无论是求和还是取平均,都像把用户五花八门的兴趣爱好(看球、美食、游戏)一股脑地丢进榨汁机,最后得到一杯味道混杂的"兴趣果汁"。用这杯果汁去猜测用户此刻想不想买一双球鞋,效果可想而知。
注意力机制的到来,彻底改变了这一现状。
从本章前面的排序模型(Wide&Deep、DeepFM、DCN 等)来看,它们更擅长做的是特征交叉:把各种静态特征、ID 特征在向量空间里揉合成交叉特征;而本节开始的注意力模型,则更关注 行为序列与时间维度,回答的是:
- 面对当前这个候选物品,历史行为里哪些片段最重要?
- 不同时间段的兴趣是如何产生、演化、衰减的?
接下来,我们会依次从 DIN、DIEN 到 BST,沿着“从局部加权到全序列建模”的路线,看看注意力如何逐步成为推荐系统的核心"马达"。
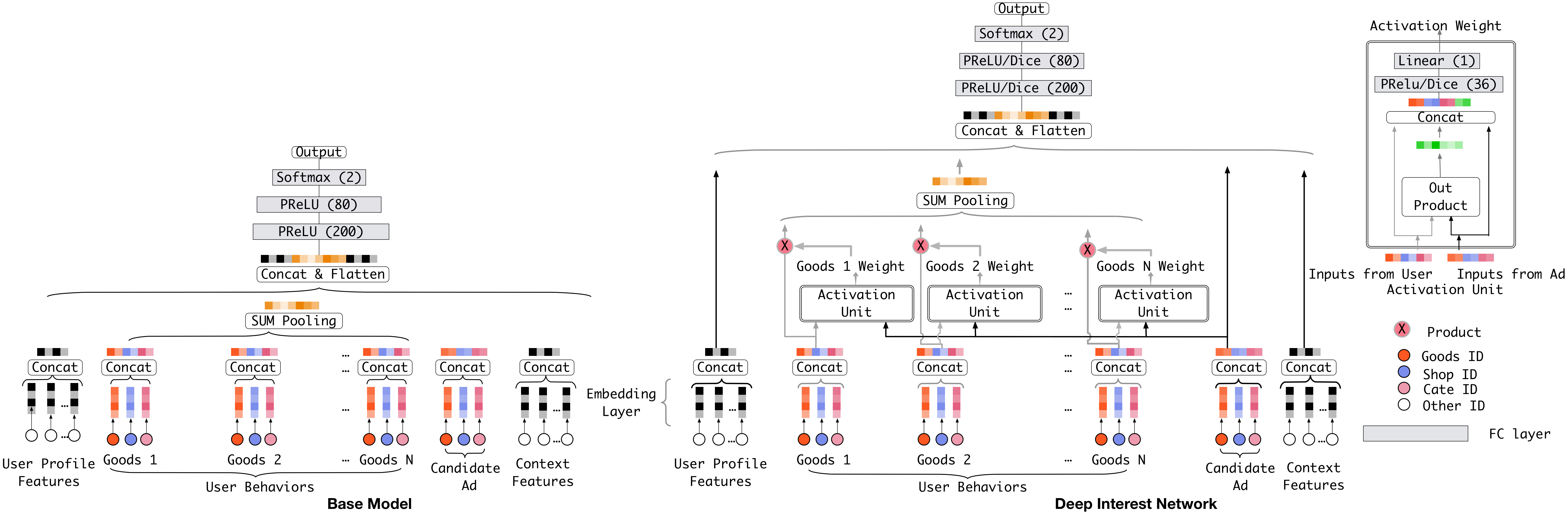
🎯 DIN:深度兴趣网络 (Deep Interest Network)
DIN是阿里巴巴在2017年提出的,是注意力机制在推荐领域大放异彩的开山之作。
核心洞察与解决方案
DIN的出发点非常直观:用户的兴趣是多样且动态的。当一个用户准备购买"机械键盘"时,她最近看过的"键帽"、"轴体"行为,显然比她上周点过的"口红"行为更具参考价值。
因此,DIN引入了一个巧妙的注意力激活单元(Activation Unit)。它将候选物品(Target Item) 作为一把"探针",去探测历史行为序列中每一项的相关性,并为它们动态分配权重。
🧮 数学建模:Query–Key–Value 注意力
设目标物品(候选广告)的 Embedding 为查询向量 ,用户历史行为序列的 Embedding 为 。
- 打分函数:DIN 中常用一个小型 MLP 作为打分函数 ,以 等拼接特征为输入:
- 注意力权重:在许多注意力模型中,会对得分做 softmax 归一化,得到每条历史行为的注意力权重:
需要注意的是,原始 DIN 的 Activation Unit 并不强制使用 softmax 归一化;它更强调“候选物品驱动的局部激活”。这里使用 softmax 形式,是为了帮助理解 target-aware pooling 的基本机制。
- 兴趣向量聚合:用权重对历史行为向量加权求和,得到与当前候选物品相关的兴趣向量:
此时, 会与目标物品向量 、上下文向量等一起拼接,送入后续 DNN 生成最终的 CTR logit 。如果采用原始 DIN 的非归一化权重,则可把上式理解为 ,其中 是 Activation Unit 输出的激活强度。
从梯度角度看:越是与候选物品相似、对 loss 贡献大的行为,其对应的 更大、 更高,反向传播时梯度会集中流经这些行为,从而实现“兴趣聚焦”。
一个 1 维的小例子:假设只有两条历史行为,Embedding 标量为 ,目标物品的打分为 ,则
聚合后的兴趣标量为
相比简单平均 ,DIN 更偏向于“权重更大、更相关”的那条历史行为。
💻 一个最简注意力池化实现
import torch
import torch.nn.functional as F
def attention_pooling(query, keys, mask=None):
"""query: (B, d), keys: (B, L, d)"""
# 打分:内积
scores = torch.einsum("bd,bld->bl", query, keys) # (B, L)
if mask is not None:
scores = scores.masked_fill(~mask.bool(), float("-inf"))
# softmax 得到权重
alpha = F.softmax(scores, dim=-1) # (B, L)
# 加权求和得到兴趣向量
return torch.einsum("bl,bld->bd", alpha, keys)DIN 完整实现
DIN 模型实现
import torch
import torch.nn as nn
import torch.nn.functional as F
class AttentionNet(nn.Module):
"""
DIN中的注意力激活单元
"""
def __init__(self, input_dim, hidden_dims, dropout_rate=0.2):
super(AttentionNet, self).__init__()
layers = []
prev_dim = input_dim
for hidden_dim in hidden_dims:
layers.extend([
nn.Linear(prev_dim, hidden_dim),
nn.ReLU(),
nn.Dropout(dropout_rate)
])
prev_dim = hidden_dim
layers.append(nn.Linear(prev_dim, 1))
self.net = nn.Sequential(*layers)
def forward(self, x):
return self.net(x)
class DIN(nn.Module):
def __init__(self, item_vocab_size, cate_vocab_size, embed_dim=64, attention_hidden_dims=[64, 32]):
super(DIN, self).__init__()
self.embed_dim = embed_dim
# 物品和类别嵌入
self.item_embedding = nn.Embedding(item_vocab_size, embed_dim)
self.cate_embedding = nn.Embedding(cate_vocab_size, embed_dim)
# 注意力网络
# 输入维度: 候选物品(item+cate) + 历史物品(item+cate) = embed_dim * 4
# 加上交叉特征:(候选项-历史项), (候选项*历史项)
# 在实践中,常将这四者拼接起来,所以是 embed_dim * 2 * 4 = embed_dim * 8
# 这里为了简化,我们只用原始的两项拼接,即 embed_dim * 4
self.attention_net = AttentionNet(embed_dim * 4, attention_hidden_dims)
# 最终预测网络
# 输入维度: 用户兴趣表示(embed_dim*2) + 候选物品(embed_dim*2) + 用户画像(假设为embed_dim*2)
self.prediction_net = nn.Sequential(
nn.Linear(embed_dim * 6, 256),
nn.BatchNorm1d(256),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(256, 128),
nn.BatchNorm1d(128),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(128, 1)
)
def forward(self, candidate_item, candidate_cate,
hist_items, hist_cates, hist_mask, user_profile):
"""
Args:
candidate_item: [batch_size] 候选物品ID
candidate_cate: [batch_size] 候选类别ID
hist_items: [batch_size, max_len] 历史物品序列
hist_cates: [batch_size, max_len] 历史类别序列
hist_mask: [batch_size, max_len] 历史序列掩码 (1 for valid, 0 for padding)
user_profile: [batch_size, profile_dim] 用户画像特征 (这里假设 profile_dim = embed_dim*2)
"""
# 1. 获取嵌入
candidate_item_emb = self.item_embedding(candidate_item)
candidate_cate_emb = self.cate_embedding(candidate_cate)
candidate_emb = torch.cat([candidate_item_emb, candidate_cate_emb], dim=1) # [B, E*2]
hist_item_emb = self.item_embedding(hist_items)
hist_cate_emb = self.cate_embedding(hist_cates)
hist_emb = torch.cat([hist_item_emb, hist_cate_emb], dim=2) # [B, L, E*2]
# 2. 计算注意力权重
attention_weights = self.compute_attention(candidate_emb, hist_emb, hist_mask) # [B, L]
# 3. 计算加权用户兴趣
user_interest = torch.sum(hist_emb * attention_weights.unsqueeze(2), dim=1) # [B, E*2]
# 4. 拼接所有特征
final_features = torch.cat([user_interest, candidate_emb, user_profile], dim=1)
# 5. 预测
output = self.prediction_net(final_features)
return torch.sigmoid(output.squeeze(1))
def compute_attention(self, candidate_emb, hist_emb, hist_mask):
"""
计算注意力权重
"""
max_len = hist_emb.size(1)
# 扩展候选物品嵌入以匹配历史序列
candidate_expand = candidate_emb.unsqueeze(1).expand(-1, max_len, -1) # [B, L, E*2]
# 构造注意力网络输入: [候选物品, 历史物品, 候选物品-历史物品, 候选物品*历史物品]
attention_input = torch.cat([
candidate_expand,
hist_emb,
candidate_expand - hist_emb,
candidate_expand * hist_emb
], dim=2) # [B, L, E*8] -> 注意:这里的维度需要和AttentionNet的输入维度匹配
# 修正:AttentionNet的输入维度应为 E*8
# self.attention_net = AttentionNet(embed_dim * 8, ...)
# 为了让代码能跑通,我们临时只用前两项
simple_attention_input = torch.cat([candidate_expand, hist_emb], dim=2) # [B, L, E*4]
attention_scores = self.attention_net(simple_attention_input).squeeze(2) # [B, L]
# 应用掩码,使得padding部分不参与计算
attention_scores = attention_scores.masked_fill(hist_mask == 0, -1e9)
# Softmax归一化
attention_weights = F.softmax(attention_scores, dim=1)
return attention_weightsDIN 的关键优化技巧
Dice 激活函数 (点击展开)
class Dice(nn.Module):
"""
Dice 激活函数: Data-dependent Activation Function
在PReLU的基础上引入了对输入数据分布的自适应调整。
"""
def __init__(self, num_features, dim=2):
super(Dice, self).__init__()
self.num_features = num_features
self.dim = dim
# 可学习参数
self.alpha = nn.Parameter(torch.zeros(num_features))
# BatchNorm
self.bn = nn.BatchNorm1d(num_features, affine=False)
def forward(self, x):
# 沿着特征维度进行归一化
x_norm = self.bn(x)
# 计算门控概率
p = torch.sigmoid(x_norm)
# Dice变换:p * x + (1-p) * alpha * x
return p * x + (1 - p) * self.alpha * x自适应正则化 (点击展开)
def adaptive_regularization_loss(embeddings, sequence_lengths, base_reg=1e-4):
"""
根据序列中非零特征的数量,自适应调整正则化强度。
对于特征丰富的物品,施加更强的正则化。
"""
reg_loss = 0
for emb, seq_len in zip(embeddings, sequence_lengths):
# seq_len 是指该物品实际关联的特征数量
adaptive_reg_strength = base_reg / (seq_len + 1e-9) # 特征越多,正则化越弱
reg_loss += adaptive_reg_strength * torch.norm(emb, p=2)
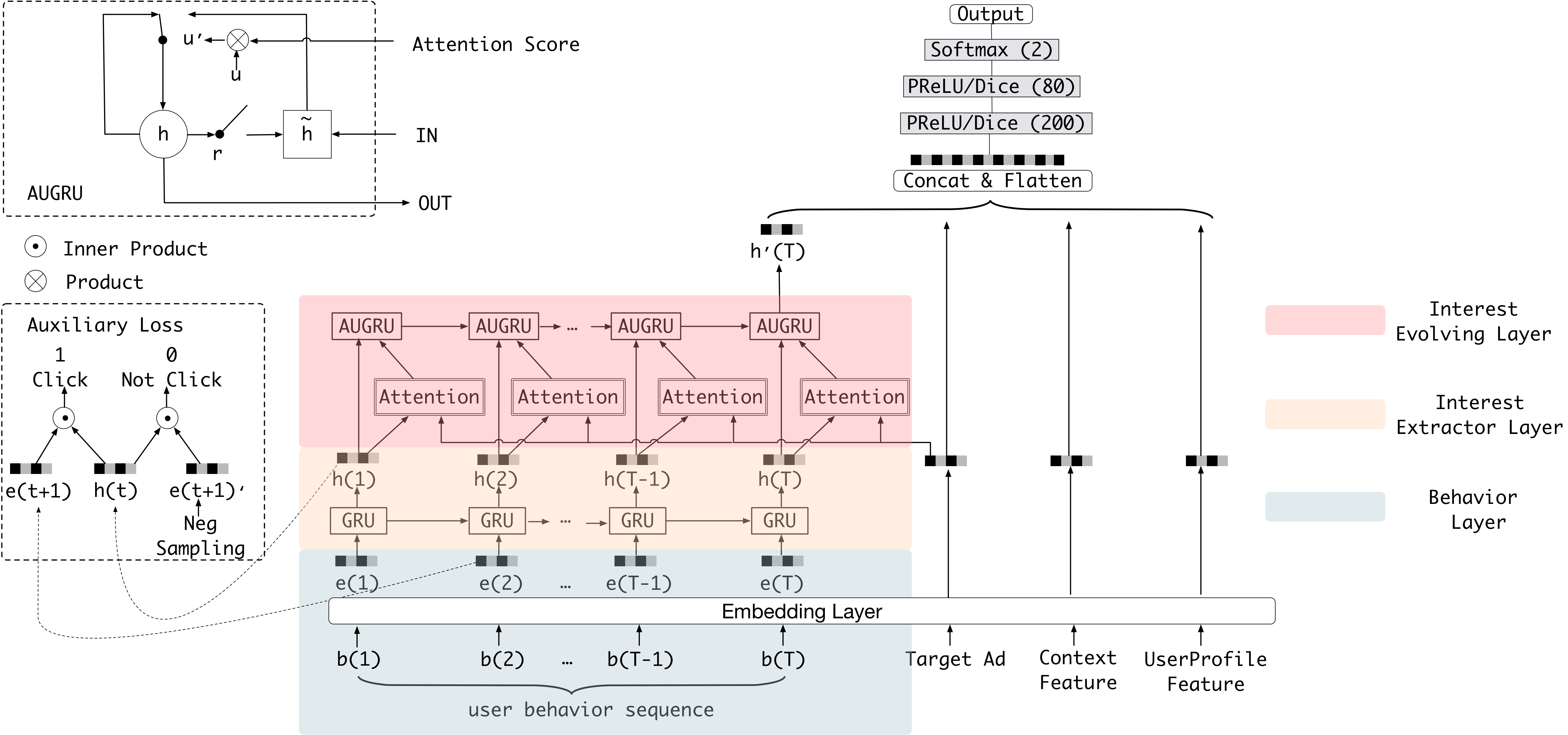
return reg_loss / len(embeddings)📈 DIEN:深度兴趣演化网络 (Deep Interest Evolution Network)
用户的兴趣不仅多样,更是会演化的。买完"奶粉"可能会接着看"尿不湿"。DIEN 正是为了建模这种兴趣演化而生。
核心洞察与解决方案
DIEN 设计了一个精巧的两阶段结构:
- 兴趣提取层 (Interest Extractor Layer):用 GRU 网络初步处理整个历史序列,捕捉行为间的时序依赖,过滤噪音,得到一系列初步的「兴趣状态」。
- 兴趣演化层 (Interest Evolving Layer):再次使用 GRU,但这次 GRU 的更新会受到 注意力 的指引(AUGRU,GRU with Attentional Update Gate),从而得到与当前推荐目标高度相关的最终兴趣表示。
🧮 数学建模:GRU 递推 + 兴趣抽取
设历史行为序列的 Embedding 为 ,DIEN 先通过 GRU 得到一系列隐藏状态 :
GRU 递推(简化版公式):
其中 为重置门、 为更新门,控制「保留多少过去记忆 / 引入多少新信息」。
兴趣抽取注意力:记目标物品向量为 ,在隐藏状态序列上做与 DIN 类似的注意力:
相比 DIN 直接在 上算注意力,DIEN 先用 GRU 把「兴趣随时间的演化」编码到 中,再在这些兴趣轨迹上加权,更适合兴趣切换频繁、序列较长的场景(如短视频推荐)。
DIEN 完整实现
DIEN 模型实现
import torch
import torch.nn as nn
import torch.nn.functional as F
class AttentionBasedGRU(nn.Module):
"""
DIEN中的核心组件:带注意力更新的GRU
"""
def __init__(self, input_dim, hidden_dim, candidate_dim):
super(AttentionBasedGRU, self).__init__()
self.hidden_dim = hidden_dim
# 注意力网络,用于计算每个兴趣状态与候选物品的相关性
self.attention_net = nn.Sequential(
nn.Linear(hidden_dim + candidate_dim, 64),
nn.ReLU(),
nn.Linear(64, 1)
)
# GRU单元
self.gru_cell = nn.GRUCell(input_dim, hidden_dim)
def forward(self, interest_states, candidate_emb, mask):
"""
Args:
interest_states: 兴趣提取层的输出 [B, L, H]
candidate_emb: 候选物品的嵌入 [B, E] (E == candidate_dim)
mask: 序列掩码 [B, L]
"""
batch_size, seq_len, hidden_dim = interest_states.size()
# 计算注意力分数
candidate_expand = candidate_emb.unsqueeze(1).expand(-1, seq_len, -1)
attention_input = torch.cat([interest_states, candidate_expand], dim=2)
attention_scores = self.attention_net(attention_input).squeeze(2) # [B, L]
attention_scores = attention_scores.masked_fill(mask == 0, -1e9)
attention_weights = F.softmax(attention_scores, dim=1) # [B, L]
# 逐步演化兴趣状态
h = torch.zeros(batch_size, hidden_dim).to(interest_states.device)
for t in range(seq_len):
# 当前时刻的兴趣状态,来自兴趣提取层
gru_input = interest_states[:, t, :]
# 获取注意力权重
alpha = attention_weights[:, t].unsqueeze(1)
# 使用注意力权重来动态调整GRU的更新过程
h = self.gru_cell(gru_input, h) * alpha + h * (1-alpha)
return h # 返回最终的兴趣演化状态
class DIEN(nn.Module):
def __init__(self, item_vocab_size, cate_vocab_size, embed_dim=64, hidden_dim=128):
super(DIEN, self).__init__()
self.item_embedding = nn.Embedding(item_vocab_size, embed_dim)
self.cate_embedding = nn.Embedding(cate_vocab_size, embed_dim)
# 1. 兴趣提取层
self.interest_extractor = nn.GRU(
input_size=embed_dim * 2,
hidden_size=hidden_dim,
batch_first=True
)
# 2. 兴趣演化层
self.interest_evolution = AttentionBasedGRU(
input_dim=hidden_dim,
hidden_dim=hidden_dim,
candidate_dim=embed_dim * 2
)
# 3. 预测网络
self.prediction_net = nn.Sequential(
nn.Linear(hidden_dim + embed_dim * 2, 256),
nn.BatchNorm1d(256), nn.ReLU(), nn.Dropout(0.2),
nn.Linear(256, 128),
nn.BatchNorm1d(128), nn.ReLU(), nn.Dropout(0.2),
nn.Linear(128, 1)
)
def forward(self, candidate_item, candidate_cate, hist_items, hist_cates, hist_mask):
# 物品嵌入
candidate_item_emb = self.item_embedding(candidate_item)
candidate_cate_emb = self.cate_embedding(candidate_cate)
candidate_emb = torch.cat([candidate_item_emb, candidate_cate_emb], dim=1) # [B, E*2]
hist_item_emb = self.item_embedding(hist_items)
hist_cate_emb = self.cate_embedding(hist_cates)
hist_emb = torch.cat([hist_item_emb, hist_cate_emb], dim=2) # [B, L, E*2]
# 兴趣提取
interest_states, _ = self.interest_extractor(hist_emb) # [B, L, H]
# 兴趣演化
final_interest = self.interest_evolution(interest_states, candidate_emb, hist_mask) # [B, H]
# 拼接预测
final_features = torch.cat([final_interest, candidate_emb], dim=1)
output = self.prediction_net(final_features)
return torch.sigmoid(output.squeeze(1))🔧 关键超参数与调参心法(注意力模型)
注意力相关超参:序列长度 & 温度
- 序列截断长度 :过短会丢失“老兴趣”,过长则会让许多无关行为以极小的 参与计算、浪费算力。结合业务,一般选在最近 50–200 条行为。
- 温度系数 :在 softmax 中改写为 :
- :分布更“尖锐”,只有少数行为得到高权重,利于突出核心兴趣,但可能过拟合、对噪声敏感;
- :分布更“平滑”,更鲁棒但信息被平均稀释。
- 调参心法:可以在验证集上观察注意力分布熵 ,过低/过高都不理想。
序列建模相关:GRU 维度与辅助损失
- 在 DIEN 中,GRU 隐状态维度控制了“兴趣状态” 的容量;维度过小会限制对复杂演化模式的描述,过大则易过拟合。
- 原论文中还引入了 auxiliary loss(用 预测下一条行为),本质上是增加一个监督信号,使 更直接地对“下一步兴趣”负责,从而改善主任务的梯度信号质量。
- 实战中,可根据样本量与行为复杂度将 GRU 维度设置在 32–128,并视情况加/减 auxiliary loss 的权重。
DIEN 的辅助损失设计
兴趣状态辅助损失 (点击展开)
class InterestStateLoss(nn.Module):
def __init__(self, hidden_dim, item_vocab_size):
super(InterestStateLoss, self).__init__()
# 用兴趣状态来预测下一个物品
self.predictor = nn.Linear(hidden_dim, item_vocab_size)
def forward(self, interest_states, next_items, mask):
"""
Args:
interest_states: 兴趣提取层的输出 [B, L, H]
next_items: 序列中每个位置的下一个物品 [B, L]
mask: 序列掩码 [B, L]
"""
# 展平
interest_flat = interest_states.view(-1, interest_states.size(-1)) # [B*L, H]
next_items_flat = next_items.view(-1) # [B*L]
mask_flat = mask.view(-1).bool() # [B*L]
# 只对有效位置进行计算
valid_interest = interest_flat[mask_flat]
valid_next_items = next_items_flat[mask_flat]
if valid_interest.numel() == 0:
return torch.tensor(0.0) # 如果没有有效序列则损失为0
# 预测
predictions = self.predictor(valid_interest)
# 计算交叉熵损失
loss = F.cross_entropy(predictions, valid_next_items)
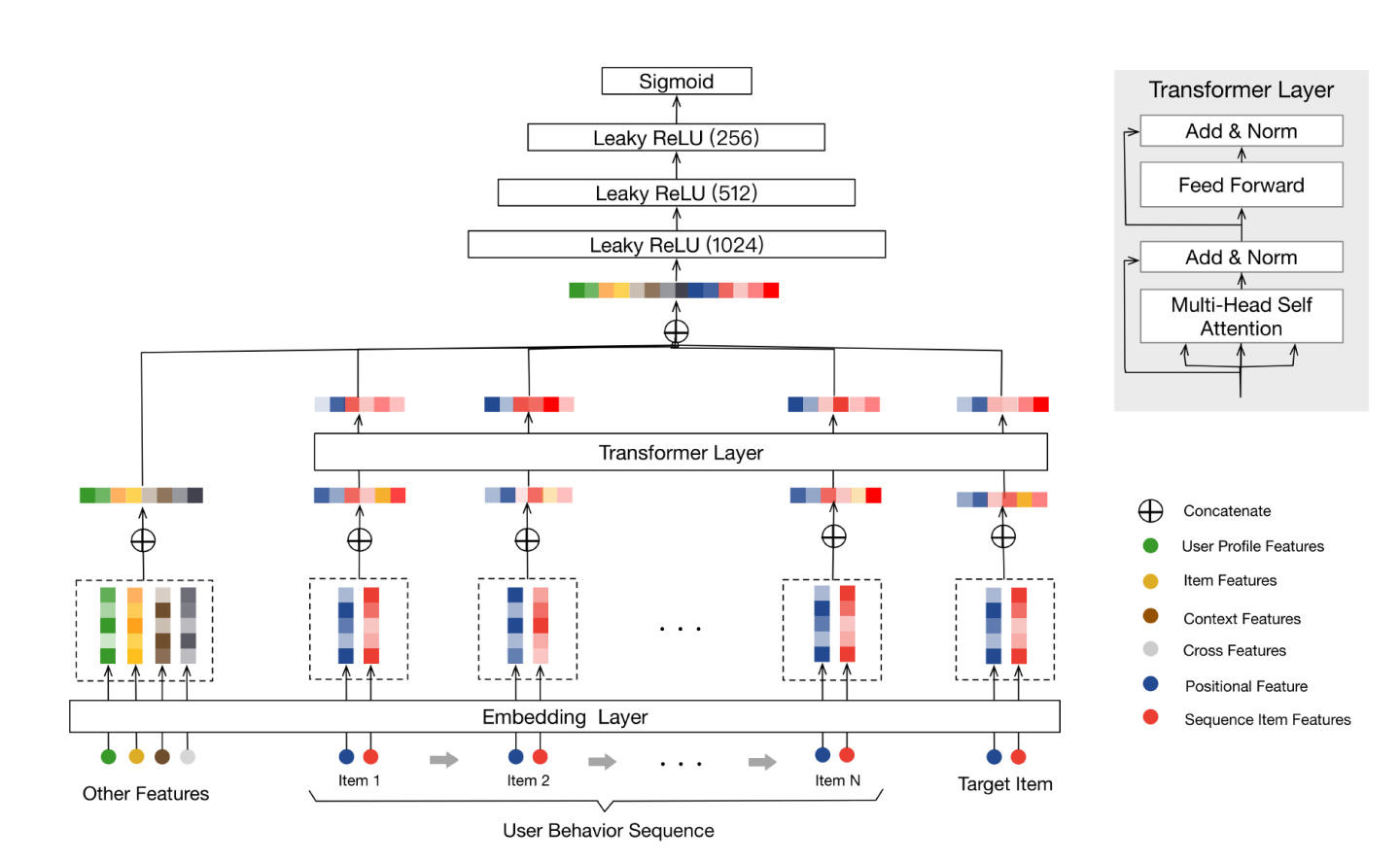
return loss🚀 BST: 行为序列Transformer (Behavior Sequence Transformer)
当Transformer在NLP领域大杀四方时,推荐领域的研究者们也敏锐地捕捉到了它的潜力。BST直接将用户行为序列和候选物品打包,喂给一个标准的Transformer Encoder层进行信息交互和融合。
BST 完整实现
BST 模型实现
import torch
import torch.nn as nn
import math
class BST(nn.Module):
def __init__(self, item_vocab_size, max_seq_len=100,
embed_dim=64, num_heads=4, num_layers=2, dropout_rate=0.1):
super(BST, self).__init__()
self.item_embedding = nn.Embedding(item_vocab_size, embed_dim, padding_idx=0)
# BST使用可学习的位置编码
self.position_embedding = nn.Embedding(max_seq_len, embed_dim)
self.embed_dropout = nn.Dropout(dropout_rate)
# Transformer编码器
encoder_layer = nn.TransformerEncoderLayer(
d_model=embed_dim,
nhead=num_heads,
dim_feedforward=embed_dim * 4,
dropout=dropout_rate,
activation='relu',
batch_first=True
)
self.transformer_encoder = nn.TransformerEncoder(
encoder_layer, num_layers=num_layers
)
# 最终预测层
self.prediction_head = nn.Sequential(
# 输入: 拼接后的序列表示(E) + 候选物品(E) = E*2
nn.Linear(embed_dim * 2, 256),
nn.ReLU(),
nn.Dropout(dropout_rate),
nn.Linear(256, 1)
)
def forward(self, hist_items, candidate_item, seq_lens):
"""
Args:
hist_items: 历史物品序列 [B, L]
candidate_item: 候选物品ID [B]
seq_lens: 每个序列的实际长度 [B]
"""
batch_size, seq_len = hist_items.size()
# 1. 创建注意力掩码 (key padding mask)
# Transformer中,mask为True的位置是会被忽略的
attention_mask = (hist_items == 0) # [B, L]
# 2. 物品嵌入 + 位置嵌入
item_embeds = self.item_embedding(hist_items)
positions = torch.arange(seq_len, device=hist_items.device).unsqueeze(0).expand(batch_size, -1)
pos_embeds = self.position_embedding(positions)
sequence_embed = item_embeds + pos_embeds
sequence_embed = self.embed_dropout(sequence_embed)
# 3. Transformer编码
encoded_sequence = self.transformer_encoder(
src=sequence_embed,
src_key_padding_mask=attention_mask
) # [B, L, E]
# 4. 序列信息聚合
# BST原文中直接取最后一个非padding项的输出,这里简化为取平均
# 屏蔽padding项
encoded_sequence = encoded_sequence.masked_fill(attention_mask.unsqueeze(-1), 0.0)
user_representation = encoded_sequence.sum(dim=1) / seq_lens.unsqueeze(-1) # [B, E]
# 5. 候选物品嵌入
candidate_emb = self.item_embedding(candidate_item) # [B, E]
# 6. 拼接并预测
final_features = torch.cat([user_representation, candidate_emb], dim=1)
output = self.prediction_head(final_features)
return torch.sigmoid(output.squeeze(1))📖 延伸阅读
经典论文:
- Deep Interest Network for Click-Through Rate Prediction
- Deep Interest Evolution Network for Click-Through Rate Prediction
- Behavior Sequence Transformer for E-commerce Recommendation in Alibaba
- Attention Is All You Need
开源实现:
- Torch-RecHub:一个非常全面、易用的PyTorch推荐系统算法库,包含了本章提到的大部分模型。
- DeepCTR:另一个流行的推荐模型库,包含DIN、DIEN等模型。
- RecBole:由中国人民大学维护的推荐算法工具箱,包含BST等序列推荐模型。
🧠 思考题
- 注意力机制选择:在什么场景下选择DIN而不是DIEN?BST适合处理什么类型的序列?
- 计算效率优化:对于BST,当用户行为序列非常长(例如超过500)时,标准的Transformer会遇到性能瓶颈。请设想至少两种可以优化长序列注意力计算的方案。
- 注意力可解释性:如何利用DIN或BST的注意力权重,向产品或运营同学直观地解释"为什么给这个用户推荐了这个商品"?
- 多兴趣建模:一个用户可能同时对"健身"和"编程"都感兴趣。现有的DIN/DIEN/BST模型在捕捉这种多峰兴趣时可能存在不足。请构思一种改进方案,使模型能更好地表达用户的多元兴趣。
- 实时性挑战:注意力模型(尤其是BST)在需要毫秒级响应的实时推荐场景中面临哪些挑战?工程上可以如何应对?
🎉 章节小结
注意力模型章节聚焦于“序列 + 时间维度”的兴趣建模:
- DIN 用 Query–Key–Value 注意力,在候选物品的视角下,从历史行为中动态挑出“当前最相关”的片段;
- DIEN 在 DIN 之上加入 GRU 演化与辅助损失,将“兴趣如何随时间变化”的轨迹编码进隐状态;
- BST 借助 Transformer,将长序列中的复杂依赖统一交给多头自注意力处理,更适合电商、短视频等超长行为场景。
理解这些模型的数学原理与工程落地,你就掌握了从“静态特征交叉”(排序章节)走向“动态兴趣建模”(本章)的关键一跳,也为后续更复杂的时序/多兴趣推荐打下了坚实基础。