推荐系统是什么?
打开抖音、快手,刷半小时全是自己喜欢的美食探店或科技测评;点开淘宝、京东,"猜你喜欢"里的衣服、数码产品刚好戳中近期需求。打开网易云、QQ音乐,每日推荐歌单比朋友更懂你的口味。就连刷微信公众号,"推荐"栏目也总能推到你感兴趣的内容……
这些渗透在生活里的场景,早已是常态。支撑这些"懂你"功能的,是同一套核心技术——推荐系统。它在不同 App 里有不同名字:电商叫"个性化推荐""猜你喜欢",内容平台叫"发现频道""为你推荐"。但本质上,它就是一个自动化的信息过滤器:在海量信息里,替你优先挑出更可能感兴趣、更有价值的内容,帮你省下在信息海洋里反复翻找的成本。
 网易云音乐的每日推荐
网易云音乐的每日推荐
我们先达成一个共识:推荐系统不是凭空出现的"黑科技",也不是工程师突发奇想的产物,而是人类为了解决"信息越来越多、精力却有限"的难题,一步步摸索出来的方案。历史脉络上,1992 年施乐公司研究中心开发的 Tapestry 系统[1],曾尝试用"找兴趣相似的人,推荐彼此喜欢的内容"的思路来做信息过滤;后续学术与工业界将这类方法体系化,逐渐形成了我们今天熟悉的"协同过滤"等技术路线。
从最初较为朴素的规则与人工筛选,到如今的复杂算法与工程系统,每一次升级都对应着我们"更高效获取信息"的需求。简单说,推荐系统的进化史,就是我们与"信息过载"的长期博弈史——不断寻找更省力、更精准的方式,从海量信息里找到自己需要的。
在深入了解前,我们先明确最简单推荐系统的两个核心组成部分,以及它的核心运作逻辑:
首先是用户(User):就是使用 App、接收推荐内容的人,比如刷抖音的你、逛淘宝的消费者、听音乐的用户。系统会通过你的行为(点击、购买、停留等)构建"兴趣画像",本质上就是给你打上一系列"兴趣标签",比如"喜欢科幻电影""常买平价护肤品""偏好轻音乐"。
其次是物品(Item):就是系统用来推荐的"内容或商品",比如抖音的视频、淘宝的衣服、网易云的歌曲、公众号的文章(在工业界也常称为"物料")。每个物品都有自己的"特征标签",比如一条视频的标签可能是"美食探店""北京""平价餐厅",一件衣服的标签可能是"女装""连衣裙""碎花""夏季"。
最简单的推荐过程,其实就是"匹配标签、传递物品"的过程:系统先收集用户的行为数据,给用户贴上兴趣标签;再给海量物品贴上特征标签;最后找出"用户兴趣标签"与"物品特征标签"匹配度最高的一批物品,主动推送给用户。比如用户标签是"喜欢美食探店",系统就把带"美食探店"标签的视频优先推给TA,这就是最基础的"把物品递给用户"的逻辑。
推荐系统为何必不可少?
要明白推荐系统为什么从"可选功能"变成了"必备工具",我们得回到没有它的时代,看看人类获取信息的方式是怎么变的。互联网发展至今,信息获取大致分三个阶段,每个阶段都有明显的痛点,这些痛点也正是推荐系统诞生和进化的原因。理清这三个阶段的变化,就能理解推荐系统存在的必要性——这也是我们接下来层层深入的基础。
第一个阶段是 20 世纪 90 年代的"信息匮乏期"。那时候互联网刚走进大众生活,网页规模远小于今天(数量级差异极大)。当时的核心问题不是"看不完",而是"找不到"。主流信息来源是门户网站,比如国外的雅虎、国内的新浪和搜狐。它们的逻辑很简单,就是"人工货架":编辑团队每天筛选重要新闻、资讯,按"新闻""体育""娱乐"分板块摆到首页,就像报纸的版面——头版是编辑认为最重要的内容,我们只能被动阅读,选择空间很小。这个阶段不需要复杂算法,有专业的"信息整理者"把内容摆整齐就行。
 1994年,门户网站标杆的雅虎,最初的界面
1994年,门户网站标杆的雅虎,最初的界面
第二个阶段是 21 世纪初的"信息增长期"。随着宽带普及、电脑降价,越来越多的人开始在网上生产内容,人工编辑模式逐渐扛不住:就算雇上很多编辑 24 小时工作,也追不上信息产生的速度。更关键的是,每个人兴趣不同,编辑的"大众眼光"难以满足个性化需求。
就在这时,搜索引擎出现了,改变了我们找信息的方式。谷歌、百度这类搜索引擎,核心是解决"人找信息"的问题:只要你知道自己想要什么,把需求变成关键词(比如"怎么学推荐系统""北京周末去哪玩"),输入搜索框,就能快速找到相关内容。它让我们找信息更主动,也打破了编辑对信息的"掌控"。但它也有明显边界:必须先"知道自己要什么"。如果你只是想"随便刷刷""打发时间",说不出精准关键词,搜索就很难派上用场。
 1998年,雅虎在首页搜索的基础上,加入广告横幅后的样式
1998年,雅虎在首页搜索的基础上,加入广告横幅后的样式
 2002年,改版为导航式的百度首页
2002年,改版为导航式的百度首页
第三个阶段是 2010 年代以后的"信息爆炸期"。随着智能手机普及,以及 4G/5G、移动支付与内容平台的发展,移动互联网与社交媒体迎来爆发式增长,我们被推入"信息过载"的状态。业内常见的监测与估算都指向同一个结论:内容生产速度远超个体的注意力供给。
在这个阶段,用户痛点发生了变化:有明确需求时,可以用搜索解决;但日常里,"无明确意图"的场景反而更多——比如通勤时想刷点视频放松、睡前想读点短文助眠、逛街时想找家符合口味的餐厅、周末想找个小众景点。这些场景下很难给出精准关键词,搜索引擎自然也就不够顺手。
正是这种"不知道自己要什么"的需求,让信息分发逻辑发生转向——从"人找信息"走向 "信息找人",而推荐系统就是实现这个转向的核心工具。它像一个专属你的"智能筛子":不用你明确表达需求,只要观察你的行为(例如停留时长、点击/划走、浏览与购买记录等),就能推测你的偏好,从海量信息里筛选并呈现更可能喜欢的内容。比如通勤时打开短视频 App,它更倾向推轻松搞笑的内容;睡前打开阅读 App,可能更倾向推舒缓的散文。这样的模式,让"随便刷刷"也能更快找到合意内容。
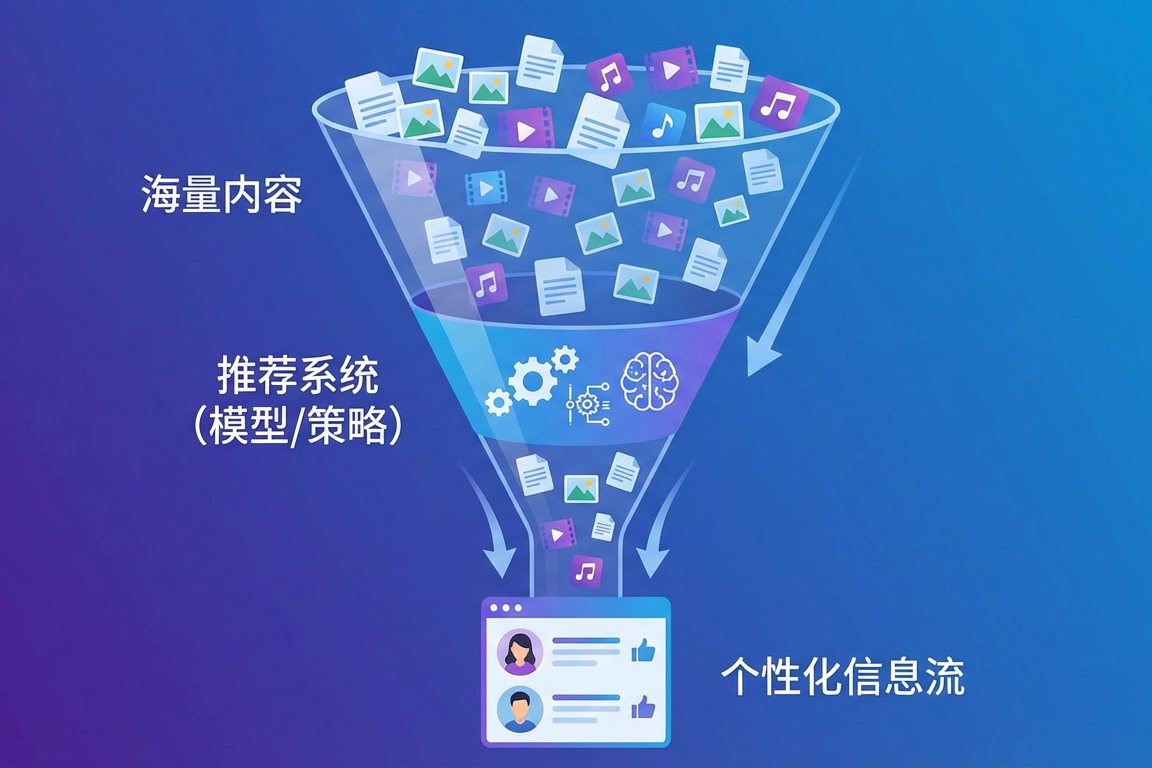 推荐系统:把海量信息过滤成更少、但更可能喜欢的内容
推荐系统:把海量信息过滤成更少、但更可能喜欢的内容
推荐和搜索,有何不同?
理解了信息获取的三个阶段,我们很自然会问:搜索引擎已经很强大了,为什么还需要推荐系统?它们的核心区别在于意图的主动性。
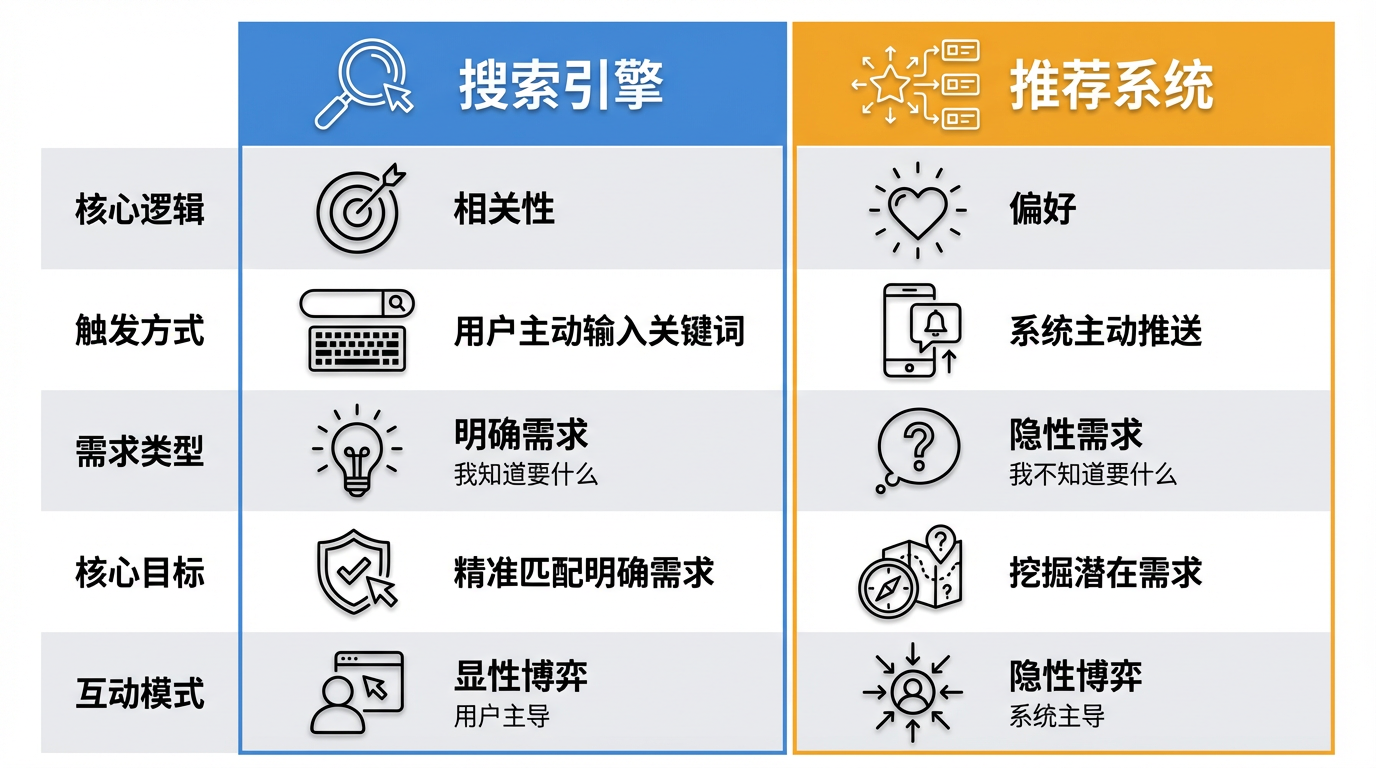 搜索 vs 推荐:主动检索 vs 被动分发
搜索 vs 推荐:主动检索 vs 被动分发
搜索引擎(Search) 解决的是"人找信息"。想象你明天要去北京出差,想知道天气情况,你会怎么办?打开百度,输入"北京明天天气",系统立刻返回最相关的天气预报。这就是搜索的逻辑:你明确知道自己要什么,主动输入关键词,系统基于相关性返回结果。它不仅是个工具,更像是在回应你的直接提问——你问一句,它答一句。
推荐系统(Recommendation) 解决的是"信息找人"。想象你周五晚上刷抖音,没有具体目标,就是想"随便刷刷"放松一下。你不知道自己想看什么,也说不出关键词,这时候搜索就派不上用场了。但推荐系统会通过分析你的历史行为(你之前喜欢看美食探店、喜欢看科技测评),基于偏好主动推送内容。它像个贴心管家,在你开口前就猜到了你的心思——不用你说,它就知道你可能喜欢什么。
两者并不是对立的,而是互补的。搜索满足明确需求,推荐挖掘潜在兴趣。在现在的 App 里,它们往往协同工作——比如你在淘宝搜过"咖啡壶",推荐流里就会出现"咖啡豆""咖啡杯""滤纸"等相关商品,搜索和推荐联手,共同覆盖了我们获取信息的全部场景。
推荐系统到底在做什么?
明确了推荐和搜索的区别后,我们来深入理解推荐系统的核心逻辑。推荐系统的精准推荐,总让人觉得"它好像懂我",其实剥掉技术外衣,它的核心目标很简单——消除不确定性。这种"不确定"是双向的:一方面是你不知道 App 里哪条内容适合自己(就像走进超大超市,货架摆满商品却不知道选哪个);另一方面是 App 不知道把哪条内容推给你,能让你更喜欢(就像超市老板不知道把什么商品放门口能卖得更多)。推荐系统的所有工作,都是为了减少这种双向的"不确定"。
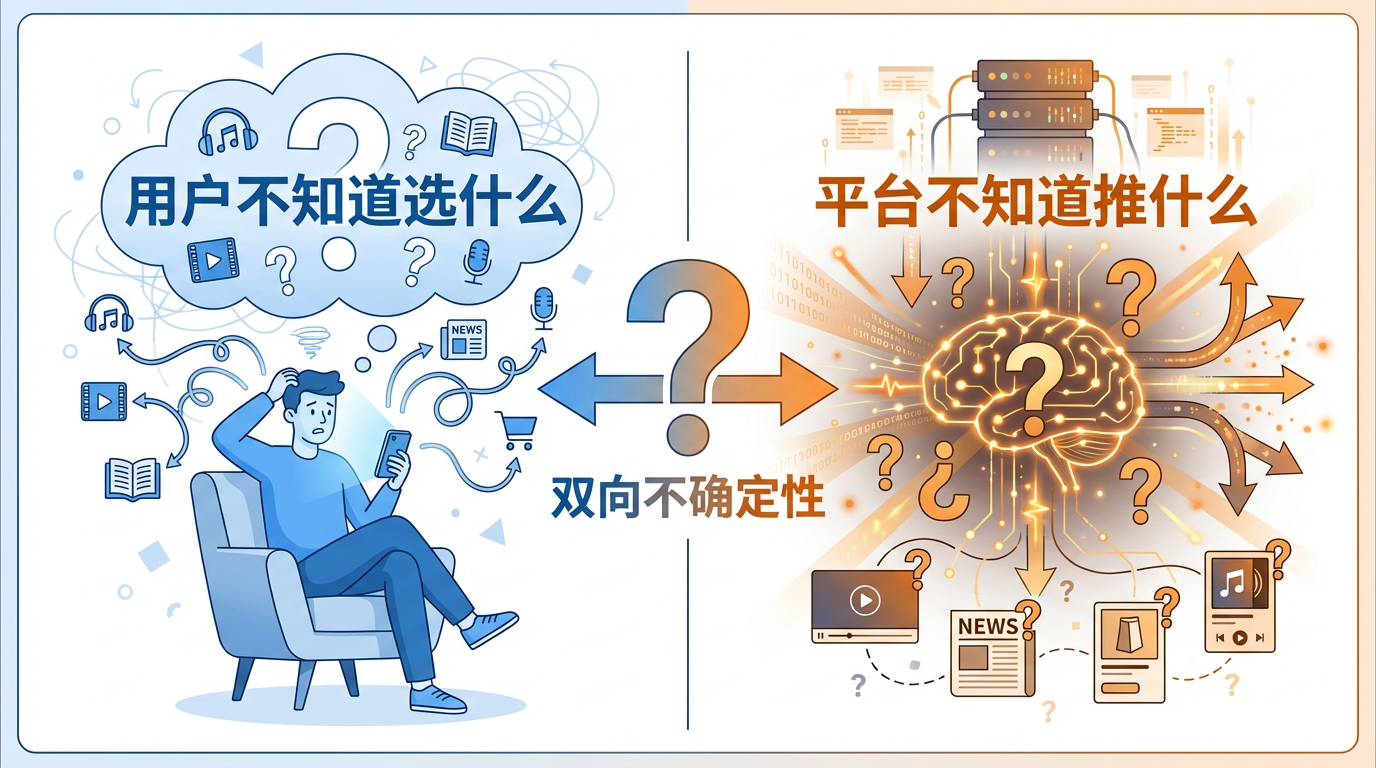 双向不确定性:用户不知道选什么,平台不知道推什么
双向不确定性:用户不知道选什么,平台不知道推什么
我们可以从两个角度清晰理解这种"不确定性":从用户的角度来看,面对一个拥有海量内容的 App(比如电商可能有上千万个商品,内容平台可能有上亿条视频),我们根本不知道哪一个内容符合自己的需求——就像走进一个巨大的超市,货架上摆满了商品,但你不知道哪一个是自己想要的,这就是用户端的"不确定性";从平台的角度来看,它拥有海量的内容和海量的用户,却不知道哪一条内容推给哪一个用户,能得到最好的用户反馈(比如点击、收藏、购买、停留)——就像超市老板不知道把哪件商品放在显眼位置能提升销量,这就是平台端的"不确定性"。而推荐系统的核心作用,就是通过数据和算法,把这种"双向不确定性"降到最低:让用户更快找到喜欢的内容,让平台的内容得到更好的利用。
经典案例:啤酒与尿布
要理解推荐系统如何消除不确定性,有个流传几十年的经典案例——"啤酒与尿布"。这个案例发生在没有互联网、没有复杂算法的线下超市,却把推荐系统最本质的道理说透了,不管有没有技术基础都能看懂。
上世纪 90 年代,零售行业开始利用超市收银数据(POS 数据)做深度分析,这类工作后来常被归入"数据挖掘"。研究者提出并系统化了"关联规则"这条路线,其中 Agrawal 与 Srikant 在 1994 年提出的 Apriori 算法,是经典代表之一。
坊间流传着一个经典故事:某大型零售商通过分析发现,"购买尿不湿的顾客,往往也会购买啤酒",尤其在周末夜间更明显。常见讲法还会配上两个指标来解释关联(不同版本的数字可能不一致,这里以示例说明概念):一是"支持度 0.03",表示每 100 笔交易里大约有 3 笔同时包含尿不湿和啤酒;二是"置信度 0.45",表示在购买尿不湿的交易中,大约 45% 同时购买了啤酒。它之所以让人觉得反直觉,是因为尿不湿与啤酒看似属于完全不同的消费场景。
 啤酒与尿布案例
啤酒与尿布案例
即便故事细节在不同来源中有所出入,它仍然很好地说明了一个要点:数据里可能隐藏着人类直觉不容易想到的行为模式。一种常见解释是:在特定时间段,部分家庭由父亲在下班路上顺带购买尿不湿;在完成"家庭任务"后,顺手买点啤酒作为放松,于是形成了高频组合。无论你是否把它当作严格可考的历史事实,这个案例都足以帮助理解"关联挖掘"的直觉。
在一些版本的叙述中,商家随后做了陈列与促销策略调整(例如把啤酒陈列放在尿不湿附近),并获得了可观的销售提升。这里不必纠结具体涨幅数字,更关键的是:一个看似简单的运营动作背后,体现了现代推荐系统/智能营销的两大核心逻辑,也是实现"个性化适配"的关键支撑。
第一是关联挖掘:通过分析海量的历史数据,找到人类直觉难以察觉的隐秘联系。就像从几十万份交易账单中,发现"买尿不湿的人大概率会买啤酒"这种反直觉的关联一样,现在的推荐系统也是通过分析亿万条用户行为数据(比如点击、收藏、购买、停留时长、分享、评论,甚至是快速划过的"厌恶信号"),挖掘用户兴趣与内容/商品之间的深层关联。比如视频 App 发现"喜欢看美食探店的用户,大概率也喜欢看厨具测评",电商平台发现"买笔记本电脑的用户,近期大概率会买鼠标和键盘",这些关联都是通过数据挖掘发现的,靠人工直觉很难预判。
第二是决策辅助:在最合适的时间和场景下,把关联内容呈现在用户面前,最大限度降低用户的决策成本和寻找成本。把啤酒放在尿不湿旁边,让父亲们不用在母婴区和酒水区之间来回奔波,减少了寻找成本;现在的推荐系统也是如此——你在电商平台买了笔记本电脑后,页面立刻推荐鼠标、键盘、电脑包,不用你再单独搜索;你在视频 App 看完一条美食探店视频后,立刻推送同类型的探店内容,不用你再翻找。这种"在需求发生时,精准推送关联内容"的模式,就是推荐系统"决策辅助"价值的核心体现。
三类核心数据
理解了"关联挖掘"和"决策辅助"的逻辑后,我们来看推荐系统具体收集哪些数据来完成"消除不确定性"的任务。
首先是用户的历史反馈数据,这是构建用户兴趣画像的核心。你过去点击了什么内容、收藏了哪些商品、购买了什么东西、对哪条内容进行了评论、停留了多长时间,甚至是你快速划过某个内容时的"厌恶信号"(比如划走速度极快)、对某个内容的"负面反馈"(比如点击"不感兴趣"),这些数据都会被系统记录下来,作为判断你兴趣的依据。想象你在抖音刷视频,每刷一条视频的停留时长、是否点赞、是否评论、是否快速划走,都在向系统"投票"——告诉它你喜欢什么、不喜欢什么。
其次是物品特征数据,这是描述内容/商品的基础。电商商品有类别、价格、材质、品牌、风格,视频内容有曲风、主题、时长、创作者,文章有领域、字数、作者。这些数据能帮助系统清晰"认识"每一个物品。比如一件连衣裙,系统会知道它是"女装 - 连衣裙 - 雪纺 - 碎花 - 夏季款",这样当系统判断你喜欢碎花夏季裙装时,就能把这件裙子推给你。
最后是上下文环境数据,这是提升推荐精准度的关键。你使用 App 的时间(是早上通勤还是晚上睡前)、所在地点(是家里、公司还是旅游景点)、使用的设备(是手机、电脑还是平板)、当前的网络环境(是 Wi‑Fi 还是流量),甚至是当天的天气(比如下雨天推荐雨伞、晴天推荐防晒霜),这些环境数据能让推荐更贴合当下场景。比如你早上 8 点打开音乐 App,系统可能推活力满满的流行乐帮你提神;晚上 11 点打开,可能推舒缓的轻音乐助眠。
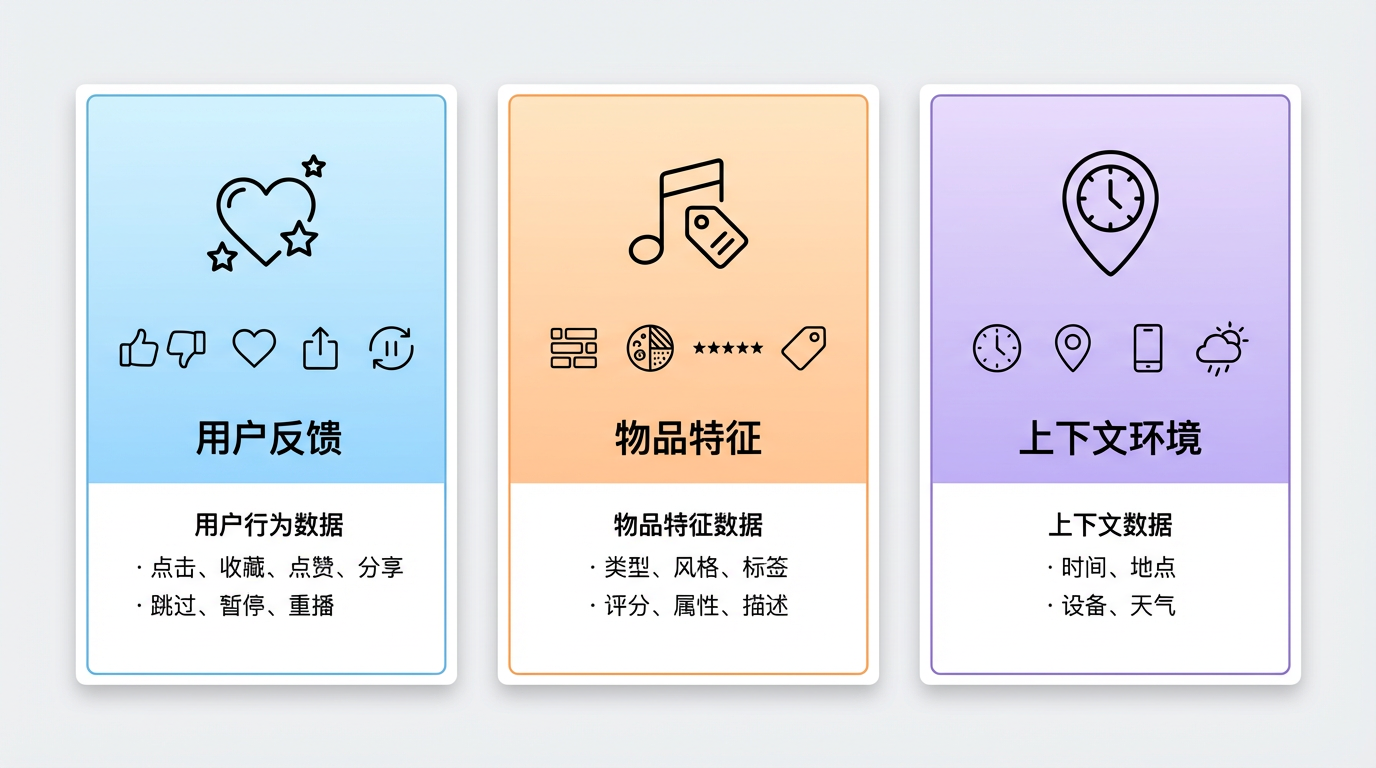 三类数据:用户反馈、物品特征、上下文环境
三类数据:用户反馈、物品特征、上下文环境
收集完这三类数据,推荐系统会用一系列算法(比如之前提到的协同过滤,还有逻辑回归、深度学习等,这些具体算法我们后续章节会详细讲,这里先知道核心作用就行),建一个"用户兴趣预测模型"。这个模型的唯一任务,就是算一个"概率分":你对某条内容/某个商品感兴趣的可能性有多大。得分越高,说明你越可能喜欢;得分越低,可能性越小。最后系统把得分最高的一批内容/商品,优先推给你。简单说,推荐系统就像你的专属"智能管家":24 小时观察你的喜好,从海量资源里挑出你最可能喜欢的,主动送到你面前,不用你自己动手找。
需着重强调的是,推荐系统的价值并不只在"提升转化"。在公开报道与业内分享中,经常能看到类似结论:电商与内容平台的相当一部分成交/消费时长,来自推荐驱动的曝光与分发(不同公司、不同口径会有差异)。
更重要的是,推荐系统重塑了我们获取信息的方式,甚至改变了认知路径:在搜索引擎主导的信息时代,更像"提问 → 回答"——用户先明确问题,再用关键词检索;在推荐系统主导的场景里,更像"反馈 → 接收"——用户不必明确表达需求,只需对内容给出正向/负向反馈(如点赞、收藏为正向反馈,划走为负向反馈),系统据此持续调整分发方向,实现与兴趣的动态匹配。它既能满足既有兴趣,也可能拓展认知边界——例如偏好爵士的用户,会被推荐到带爵士元素的流行乐,从而接触到新的音乐类型。
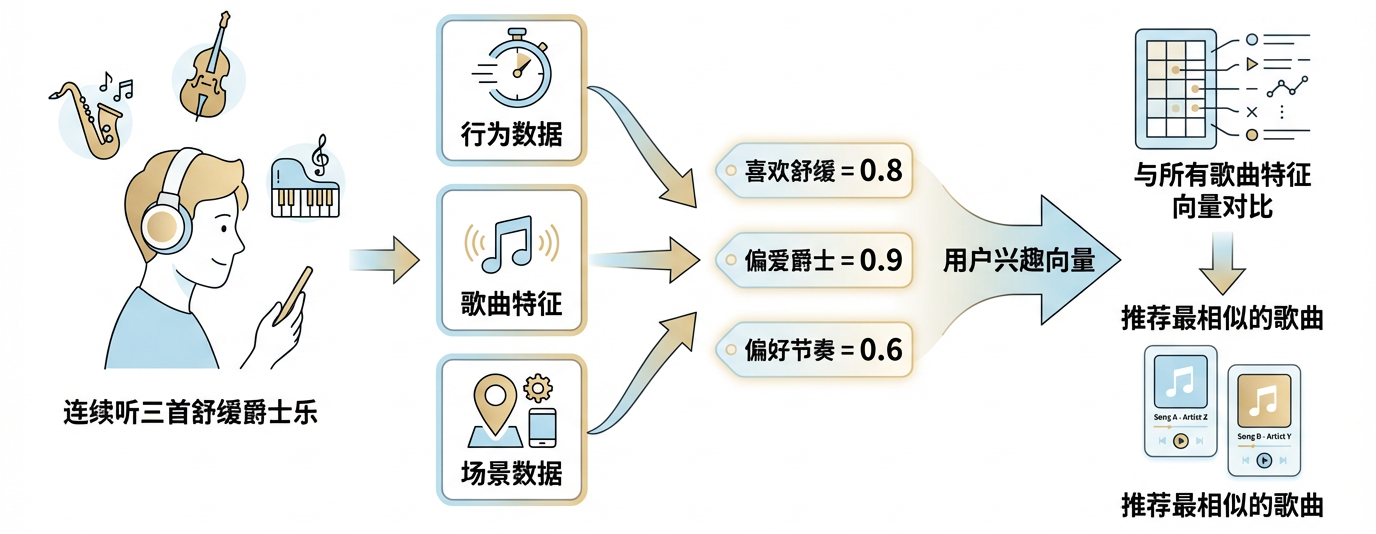 推荐音乐的过程
推荐音乐的过程
现阶段推荐系统的核心:多级架构(召回-粗排-精排-重排)
前面我们讲了推荐系统的基础逻辑,但实际应用中,平台的物品库规模极大(比如电商有上千万商品、视频平台有上亿条视频)。如果直接对所有物品做精准评分,不仅耗时极长(用户等不及),还会耗费大量服务器资源(成本太高)。为了解决"精准度"和"效率"的矛盾,现阶段工业界几乎都采用"召回-粗排-精排-重排"的多级架构——就像筛选人才,先通过简历初筛(召回),再快速面试(粗排),最后详细面试(精排),甚至补充一轮适配调整(重排),既保证能选出合适的人,又不浪费时间。
简单说,多级架构的核心目的是:从海量物品中,以"由粗到细、层层筛选"的方式,快速找到既符合用户兴趣、又满足平台需求的优质物品,平衡"效率"(快速筛选)和"效果"(精准推荐)。下面我们逐一拆解每一层的作用:
 推荐系统多级架构图
推荐系统多级架构图
1. 召回:从"全量物品"中圈出"可能感兴趣"的候选集
召回是推荐的第一步,核心目标是"快速圈定范围"——从平台的全量物品库(比如上亿条视频)中,快速找出几千到几万条用户"可能感兴趣"的物品,形成一个"候选集"。这一步的关键是"快"和"全",不追求极致精准,但要尽量把用户可能喜欢的物品都包含进来(避免漏掉好内容)。
比如你喜欢"美食探店"视频,召回层就会通过简单的匹配逻辑(比如标签匹配:用户标签=美食探店,物品标签=美食探店;或相似推荐:找和你之前点赞视频相似的内容),从上亿条视频里,快速挑出几千条带"美食"相关标签的视频,作为候选集。它的逻辑很简单,就像你去超市,先根据自己的大致需求(想吃零食),从整个超市里走到零食区,把零食区的所有商品都当作"候选",不纠结具体选哪一款。
召回层常用的方法有:基于用户/物品标签的匹配、协同过滤(找相似用户喜欢的物品)、热门物品兜底(避免新用户没数据时无内容可推)等。这些方法的特点是计算简单、速度快,能在毫秒级完成从海量物品到候选集的筛选。
2. 粗排:对"候选集"做快速排序,缩小范围
经过召回层后,我们有了几千到几万条候选物品。如果直接进入精准计算,成本还是太高,所以需要"粗排"这一步——核心目标是"快速瘦身",用简单的模型和少量特征,对候选集里的物品快速打分排序,筛选出几百条更可能符合用户兴趣的物品,进入下一层。
这一步就像你在超市零食区,快速扫一眼所有零食,根据简单的标准(比如价格是否在预算内、是不是自己常买的品牌),把不符合的(比如太贵的、从没吃过的小众品牌)排除,剩下几十到上百款重点候选。粗排层的模型比召回层复杂一点,但比精排层简单很多,不会用太多复杂特征(比如不会细致分析你对每款零食的历史评价),只抓核心信息(比如用户是否喜欢该品类、物品的基础热度),确保在极短时间内完成排序。
粗排的关键是"平衡速度和效果":既要比召回层更精准地筛选,又要保持极快的计算速度,为后续精排节省资源。
3. 精排:核心决策层,精准预测用户偏好
精排是整个推荐系统的"核心决策层",核心目标是"极致精准"——用复杂的模型(比如深度学习模型)和海量特征(包括用户历史行为、物品详细特征、上下文环境等),对粗排筛选出的几百条物品做精准打分。这个分数是对"用户喜欢该物品的概率"最精准的预测,得分越高,用户喜欢的可能性越大。
这一步就像你在重点候选的零食里,仔细对比每一款的细节:比如配料表是否健康、有没有添加剂、之前吃的评价如何、现在有没有优惠活动等,最后选出最符合自己需求的几款。精排层会用到我们之前提到的三类核心数据(用户反馈、物品特征、上下文),模型会细致分析每一个特征的影响——比如不仅知道你喜欢零食,还知道你喜欢"低糖、独立包装、适合办公室吃"的零食,从而精准匹配。
精排层的模型复杂、计算成本高,但因为前面已经经过召回和粗排的筛选,物品数量只有几百条,所以整体成本是可控的。这一步的打分结果,直接决定了大部分物品的最终推荐顺序。
4. 重排:微调细节,优化最终体验
经过精排后,物品的排序已经很精准了,但还可能存在一些问题:比如推荐的10条内容全是同一类(比如全是川菜探店视频),用户会觉得单调;或者有一些高风险内容(比如敏感话题)需要规避;又或者平台有特殊需求(比如扶持新创作者的内容)。这时候就需要"重排"这一步——核心目标是"体验兜底与平台目标适配",在精排的基础上做细节微调。
重排的具体操作包括:打散同类内容(比如在川菜探店视频中插入1条粤菜视频,增加多样性)、规避敏感/低质内容、优先展示平台重点扶持的内容、调整物品展示顺序(比如把短视频和长视频穿插排列)等。这一步就像你最终选好了零食,在结账前再看一眼:如果选的全是薯片,就加一包坚果平衡一下;如果有一款零食快过期了,就换成新鲜的。
重排层的模型通常比较简单,更多是基于规则和简单的优化目标,目的是在不破坏精排精准度的前提下,让最终推荐结果更符合用户的实际体验需求和平台的长期目标。
总结一下多级架构的逻辑:召回负责"广撒网",粗排负责"快筛选",精排负责"精准选",重排负责"调细节"。从全量物品到最终推荐的几十条内容,层层筛选、由粗到细,既保证了推荐的精准度,又控制了计算成本和响应时间,这也是为什么我们打开App时,能在瞬间看到符合自己兴趣的内容。
参考文献
[1] Goldberg, D., Nichols, D., Oki, B. M., & Terry, D. (1992). Using collaborative filtering to weave an information tapestry. Communications of the ACM, 35(12), 61-70.