评测体系:线上与离线,谁说了算?
推荐系统在不同业务场景中有着不同的核心目标,比如电商追求转化,内容平台看重停留时长。但如何判断一个推荐系统的好坏?怎样衡量它是否达成了业务目标?这就需要一套完整的"尺子"——也就是评测体系。
推荐系统的评测体系主要分为两大块:离线评测与在线评测。离线评测就像实验室里的"模拟考",在模型上线前筛掉不合格的方案;在线评测则是真实环境中的"实战",直接对接业务效果。除此之外,还有一些看似"虚无缥缈"却能决定用户体验的"魔法"指标。而 A/B Test,就是连接离线与在线、验证系统真实价值的关键桥梁。
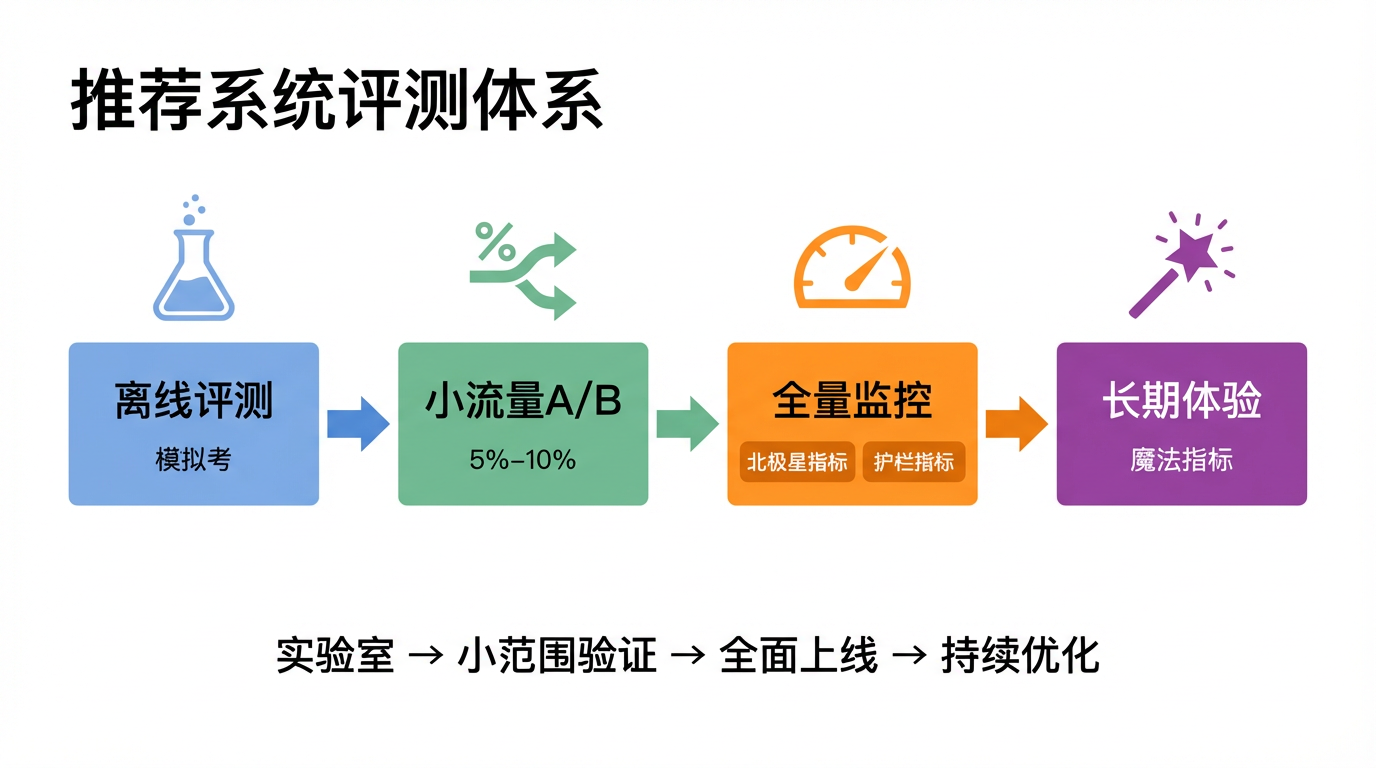 评测总览:离线筛选、线上验证、护栏防风险、长期看体验
评测总览:离线筛选、线上验证、护栏防风险、长期看体验
离线评测:用历史数据做"模拟考"
离线评测的基本流程如下:把历史日志切成训练集和测试集,让模型在训练集学习,在测试集上打分。这里有个非常重要的事实:离线评测里我们并不知道"用户真正喜欢的全集"。所谓的"正确答案",通常用测试集里的正反馈来近似(例如:用户在某个时间窗里点击/购买过的物品)。所以离线评测衡量的是"能否复现历史行为",而不是"上线后一定更好"。
在进入具体指标之前,我们需要理解两个核心概念。推荐列表
举个完整的例子:假设系统给小明推荐了 10 个商品(运动鞋、手机壳、咖啡杯、键盘、鼠标、耳机、充电宝、水杯、背包、数据线),而在测试集里,小明实际点击过 5 个商品(运动鞋、键盘、耳机、充电宝、台灯)。注意,推荐列表里有台灯吗?没有!这种"漏推"会影响召回率。同时,推荐列表里推了手机壳,但小明历史里没点过,这种"瞎推"会影响准确率。接下来的所有指标,都是在衡量"推荐列表"和"真实历史"之间的匹配程度。
1.1 Precision / Recall / F1:推得准不准?
想象你是奶茶店店员,店里有几十款产品。但是我的门口广告牌有限,只给客人推荐 10 款饮品:芝士奶盖、多肉葡萄、柠檬茶、珍珠奶茶、草莓啵啵、杨枝甘露、红豆奶茶、乌龙茶、冰淇淋红茶、焦糖玛奇朵。客人最后点了其中 3 款:芝士奶盖、多肉葡萄、杨枝甘露。Precision@K(准确率) 就是 3/10 = 30%,衡量"你推荐的东西里,有多少是靠谱的"。公式表达为:
其中分子是命中数量(推荐列表和真实喜好的交集),分母
但这位客人其实对店里 5 款饮品感兴趣(芝士奶盖、多肉葡萄、杨枝甘露、烧仙草、冰淇淋波波),你只推了前 3 款,漏掉了烧仙草和冰淇淋波波。Recall@K(召回率) 就是 3/5 = 60%,衡量"用户喜欢的东西里,你能挖出来多少"。公式为:
这两个指标往往是矛盾的:如果只推 1 个最有把握的,准确率可能 100%,但召回率很低;如果推 100 个把菜单全推一遍,召回率 100%,但准确率惨不忍睹。F1@K 就是用来平衡两者的调和平均数:
奶茶店例子算出 F1 = 0.4,说明虽然召回还行,但准确率拖后腿,综合表现一般。回到电商例子:小明真实点击了 5 个商品,系统推了 10 个,命中 4 个。Precision@10 = 0.4,Recall@10 = 0.8,F1@10 ≈ 0.53。
1.2 HR / NDCG:排得好不好?
只猜对不够,还得排得好。想象你在百度搜"推荐系统教程",结果排第 1 的是垃圾广告,排第 50 的才是你真正想要的高质量课程——虽然"命中了",但体验很糟糕。推荐系统也一样:你打开抖音,第 1 条视频很无聊,你可能直接划走;但如果第 1 条就是你喜欢的,你会一直刷下去。位置决定体验。
Hit Rate@K(HR@K) 是最简单的排序指标:前 K 个推荐里,只要有 1 个用户喜欢的,就算成功。想象你是相亲节目的红娘,给小李推荐了 10 个相亲对象,只要有 1 个看对眼了,HR = 1;如果全被拒绝,HR = 0。公式为
NDCG@K(归一化折损累计增益) 则更进一步:不仅要推对,还要把最好的排在最前面。这个指标很"势利"——位置越靠前,权重越大。你打开外卖 App 点烧烤,你最喜欢的"老张烧烤"排在哪里?如果排第 1,你直接点进去下单,系统得满分;如果排第 8,你要翻半天才看到,系统得分打折;如果排第 50,你根本翻不到,系统几乎不得分。
NDCG 的计算分三步。首先算 DCG(折损累计增益):
其中
举个例子:你给用户推荐了 5 个视频,用户实际喜欢其中 3 个(第 1、3、5 位)。计算 DCG:第 1 位得分 1/1.00 = 1.00,第 2 位得分 0,第 3 位得分 1/2.00 = 0.50,第 4 位得分 0,第 5 位得分 1/2.58 = 0.39,DCG = 1.89。理想排序 IDCG = 1.00 + 0.63 + 0.50 = 2.13。NDCG = 1.89 / 2.13 ≈ 0.89,说明排序接近理想状态,但还有优化空间。NDCG 是工业界最重要的离线指标之一,因为它同时考虑了"推没推对"和"排得好不好"。
1.3 RMSE:评分预测准不准?
前面的指标都是"猜喜不喜欢"(0 或 1),但有些场景需要预测具体的评分(比如豆瓣电影的 1~5 星)。这时候就需要 RMSE(均方根误差)。想象你是豆瓣的算法工程师,要预测小王会给《肖申克的救赎》打几星。小王实际打了 5 星,你的模型预测 4.2 星,误差 0.8。RMSE 就是所有误差平方和的"平均值再开方":
为什么要"平方"再"开方"?平方能放大大误差的惩罚(误差 2 的平方是 4,误差 0.5 的平方只有 0.25),开方是为了还原到原始单位(从"星²"变回"星")。比如你预测了 4 部电影,误差平方和是 1.54,RMSE =
离线指标的局限性在于:它无法模拟真实反馈闭环,无法解决冷门内容的困境(你新推的冷门好片,用户历史里从没接触过,离线评测会给低分,但实际上线用户可能很喜欢)。所以,必须看在线指标。
在线指标:真实世界的北极星
一旦上线,我们就不再看"预测误差"了,而是看真实的商业价值和用户体验。这些指标像北极星一样,指引团队优化的方向。
CTR(点击率) 是最基础的门槛,公式为
CVR(转化率) 衡量的是:点进来的人里,有多少人完成了最终目标?公式为
Retention(留存率) 是衡量产品生死的王牌指标。如果你为了短期 CTR 拼命推低俗内容,用户明天卸载了,那留存率就崩了。公式为
除了核心指标,还要盯着一些"护栏指标"防止系统跑偏:时延(推荐响应速度,通常要求 < 200ms)、负反馈率(用户点"不感兴趣"的比例)、投诉率(推荐违规内容的比例)等。
 在线指标漏斗:从"愿意点"到"愿意再来"
在线指标漏斗:从"愿意点"到"愿意再来"
"魔法"指标:用户体验的隐形守护者
只追 CTR,推荐系统很容易变得"无聊"——总是推你之前看过的东西。为了让推荐更有"魔法",我们需要关注以下指标。
多样性(Diversity) 要求推荐列表里的东西丰富多彩,不能单调重复。你打开 B 站首页,低多样性推荐全是猫视频——虽然你喜欢猫,但会审美疲劳;高多样性推荐则涵盖萌宠、学习、音乐、美食、体育等多个兴趣点,更不容易腻。公式表达为
覆盖率(Coverage) 衡量的是:系统里有 100 万个商品/视频,推荐系统能推出来多少种?一个音乐 App 有 1000 万首歌,但推荐系统只反复推那 100 首热门歌曲,导致用户总听到同样的歌(腻了)、冷门歌手永远没有曝光机会、长尾资源被浪费。公式为
惊喜度(Serendipity) 是最高级的指标,要求推荐的东西既让你感到意外,又恰好是你喜欢的——像一个懂你的朋友。举三个场景对比:场景 A,你一直在看漫威电影,系统给你推荐《复仇者联盟 4》——你会点,但没有惊喜,这是预料之中的;场景 B,系统给你推荐了《银翼杀手 2049》(你从未搜过,但风格契合)——你点开一看:"哇,这片子太对味了!"这就是惊喜;场景 C,系统给你推荐《乡村爱情故事》——虽然意外,但你不喜欢,这不是惊喜,这是瞎推。
惊喜度的两个条件是:相关性(用户要喜欢)和意外性(和用户历史兴趣不太像)。公式为
为什么"魔法指标"很重要?短期优化 CTR,可以靠推热门爆款。但长期来看:用户会审美疲劳(多样性不足)、冷门内容永无出头之日(覆盖率低)、用户觉得系统"不懂我"(缺乏惊喜)。多样性、覆盖率、惊喜度是长期用户体验的护城河,也是留存率的关键驱动因素。
注:虽然工业界普遍认为多样性、覆盖率、惊喜度对长期用户体验至关重要,但具体的量化影响因场景而异。部分研究(如 Netflix 和亚马逊的实践)表明,优化这些指标可以显著提升用户留存和长期价值,但具体数值和影响程度需要结合自身业务场景进行 A/B 测试验证。
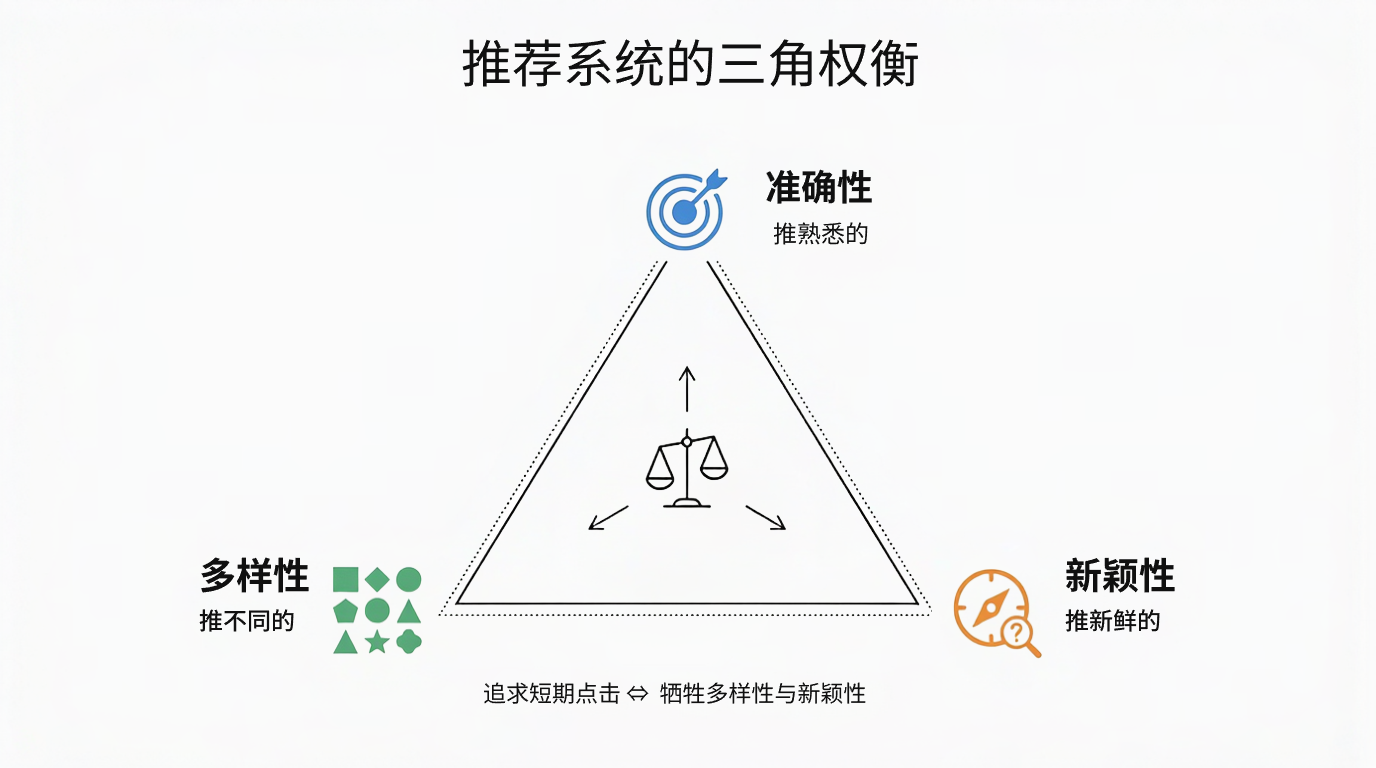 权衡:越追短期点击,越可能牺牲多样性与新颖性
权衡:越追短期点击,越可能牺牲多样性与新颖性
A/B Test:最终的裁判
既然离线指标不完全可信,在线指标又容易波动,怎么确定新模型一定比旧模型好?答案是 A/B Test(分流实验)——这是互联网公司验证新策略的黄金标准。
A/B Test 的核心是让两组用户同时使用不同的推荐策略,看哪组效果更好。对照组(A 组)使用旧策略,实验组(B 组)使用新策略,通过随机分流让用户被随机分配(保证两组用户特征相似),在相同的时间、环境下同时运行。一段时间后(通常 1~2 周),对比两组的 CTR、CVR、留存等核心指标。效果公式为
举个生活化例子:你经营一家奶茶店,想测试"买一送一"能不能提升销量。A 组 100 个顾客正常价格,B 组 100 个顾客买一送一。运行 1 周后:A 组 40 人购买(购买率 40%),总收入 600 元;B 组 70 人购买(购买率 70%),总收入 1050 元。结论:购买率提升 +30%,总收入提升 +450 元,新策略显著更好!这就是 A/B Test 的威力:用数据说话,而不是拍脑袋决策。
再看一个推荐系统实战案例。假设你是抖音的算法工程师,开发了一个新的推荐模型(加入了多样性优化)。A 组 50% 用户使用旧模型(纯 CTR 优化),B 组 50% 用户使用新模型,运行 2 周。结果:CTR 方面,A 组 22.5%,B 组 22.1%,下降 0.4%(p值 > 0.05,不显著);人均停留时长方面,A 组 35 分钟,B 组 42 分钟,提升 +20%(p值 < 0.01,显著);次日留存率方面,A 组 58%,B 组 64%,提升 +6%(p值 < 0.05,显著)。分析:CTR 略微下降,但停留时长和留存率大幅提升。综合判断:新模型更好,上线!
注:统计显著性通常使用 p 值判断,p < 0.05 表示结果有统计学意义,p < 0.01 表示结果高度显著。
为什么 A/B Test 是"最终裁判"?离线评测只能模拟历史行为,无法预测新策略的真实效果。A/B Test 的优势是:真实用户、真实环境、真实反馈,能同时观察短期指标(CTR)和长期指标(留存),能发现离线评测看不到的问题(比如新模型响应太慢)。工业界的标准流程是:
离线评测(筛选) → 小流量 A/B Test(5%~10%) → 大流量 A/B Test(50%) → 全量上线只有通过层层验证,新模型才能真正上线服务用户。
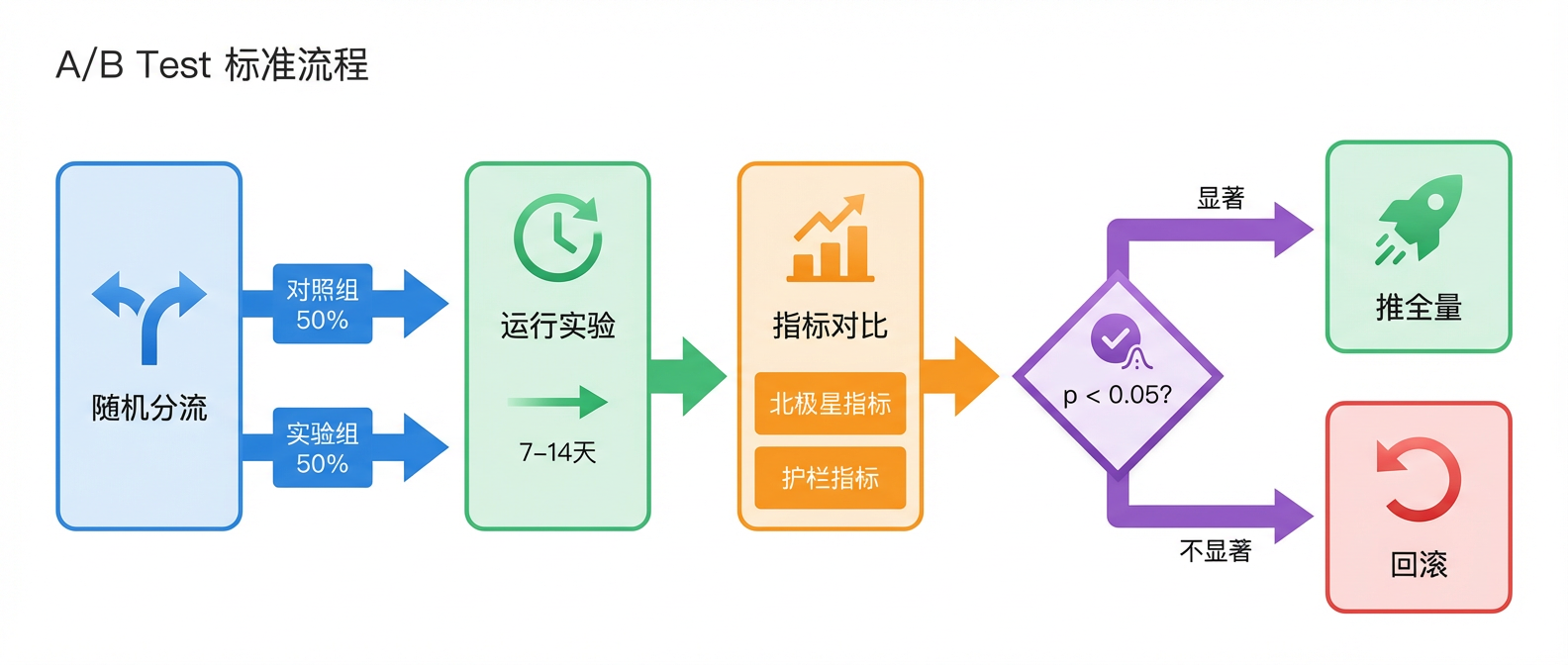 A/B Test:线上验证的标准流程
A/B Test:线上验证的标准流程