特征工程:Embedding 艺术
在第二章的最后,我们用逻辑回归实现了 CTR 预估,但 AUC 只有 0.53——仅比随机猜测好一点点。问题出在哪?
想象你是一个图书管理员,要给读者推荐书籍。如果你只知道"张三喜欢科技类书",你能推荐什么?可能是《人工智能导论》,也可能是《电脑组装指南》——这两本书差别巨大。但如果你知道"张三喜欢的书和《深度学习》很像",推荐就精准多了。
这就是我们面临的问题:如何用数学语言描述"像"这个概念?
答案就在 Embedding(嵌入) 技术中。Embedding 的核心思想很简单:给每个用户、每条新闻画一幅"数字肖像"——用一组数字(向量)来描述它的特征。相似的对象,数字肖像也相似。这幅肖像不是人工设计的,而是让模型在训练中自己学会的。
代码说明
本节代码位于 src/ch03/01_feature_embedding.py。运行前请确保:
- 已下载 MIND 数据集到
src/dataset/train/MINDsmall_train/ - 已安装依赖:
pip install torch pandas numpy - 在
src/ch03/目录下运行:python 01_feature_embedding.py
One-hot 编码的困境
在讲 Embedding 之前,我们先理解为什么需要它。
想象你要向计算机描述"体育"这个类别。计算机不懂中文,只认数字。最直接的方法是给每个类别一个"身份证号":
| 类别 | 编码 |
|---|---|
| sports | [1, 0, 0, 0] |
| tech | [0, 1, 0, 0] |
| entertainment | [0, 0, 1, 0] |
| news | [0, 0, 0, 1] |
这就是 One-hot 编码:每个类别占一个位置,自己的位置是 1,其他都是 0。看起来很合理,但有两个致命问题:
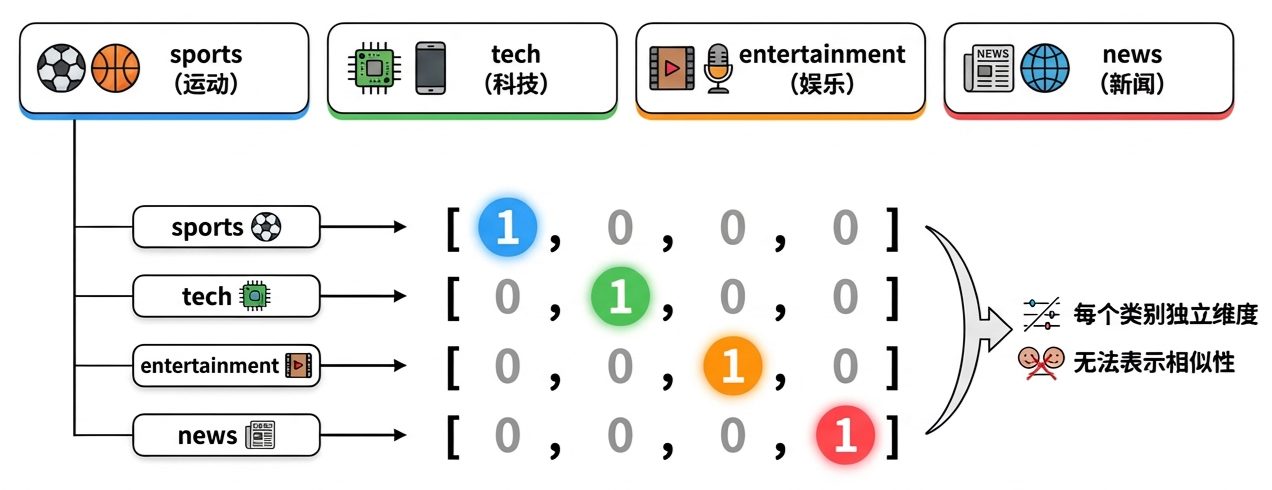 One-hot 编码:每个类别对应一个独立的维度,向量极度稀疏
One-hot 编码:每个类别对应一个独立的维度,向量极度稀疏
问题 1:维度爆炸
MIND 数据集有 51,282 条新闻和 50,000 个用户。如果用 One-hot 编码:
- 每条新闻需要一个 51,282 维的向量(只有 1 个位置是 1)
- 每个用户需要一个 50,000 维的向量
要预测"用户 U13740 是否会点击新闻 N12345",输入特征就是两个向量拼接:101,282 维!这意味着模型需要学习 10 万多个参数。如果再加上类别、子类别等特征,维度轻松突破百万。
这就像用一本 10 万页的字典来描述一个人——99.99% 的页面都是空白的,既浪费空间,又难以处理。
问题 2:无法表达相似性
One-hot 编码还有一个更隐蔽的问题:所有类别之间的"距离"都一样。
在 One-hot 的世界里,"体育"和"娱乐"的距离,等于"体育"和"科技"的距离,等于"体育"和"财经"的距离——都是 0(余弦相似度)。但在现实中,"体育"和"娱乐"明显更相似——它们都是休闲内容,喜欢看体育的人往往也喜欢看娱乐。
One-hot 编码把每个类别放在完全独立的维度上,就像把每个人关在单独的房间里——它们之间没有任何联系。
Embedding:降维打击的艺术
Embedding 的核心思想可以用一个类比来理解:
想象你要描述一个人。One-hot 的方式是列出世界上所有人的名字,然后在这个人的名字旁边打勾——这需要 70 亿个格子。而 Embedding 的方式是用几个关键特征来描述:身高 175cm、体重 70kg、年龄 25 岁——只需要 3 个数字,就能大致刻画一个人。
Embedding 就是给每个对象画一幅"数字肖像",用少量的数字(通常 32-128 个)来描述它的特征。
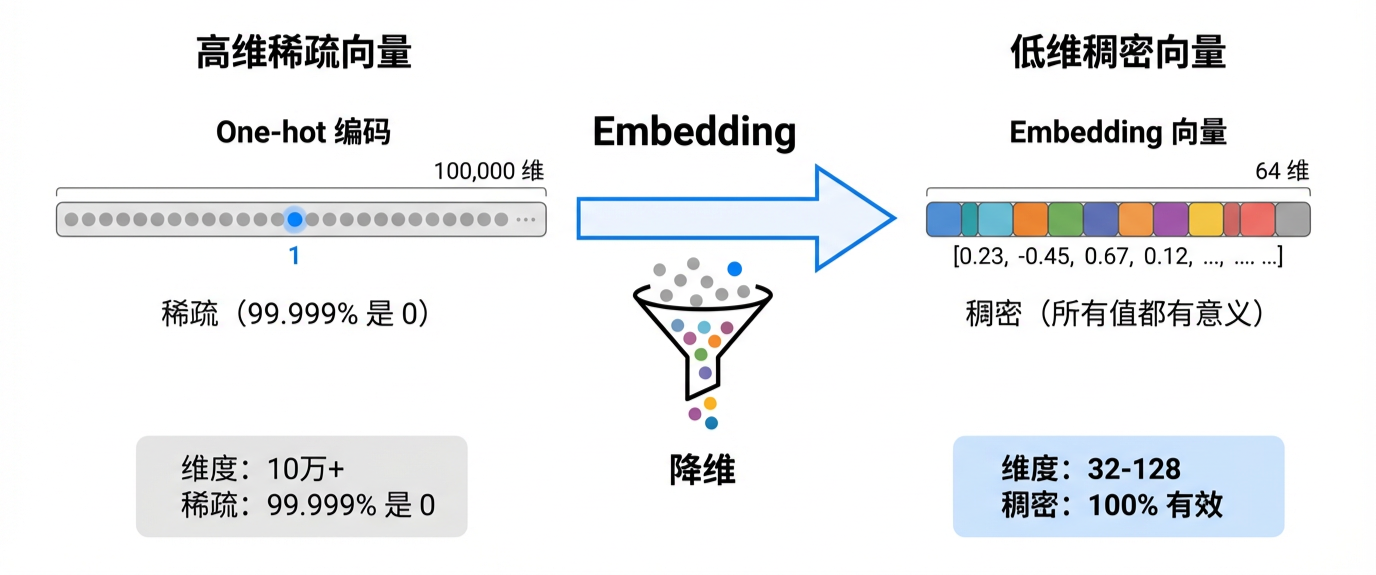 Embedding 将高维稀疏向量压缩为低维稠密向量
Embedding 将高维稀疏向量压缩为低维稠密向量
从 One-hot 到 Embedding
对比一下两种表示方式:
| 类别 | One-hot (4维,稀疏) | Embedding (2维,稠密) |
|---|---|---|
| sports | [1, 0, 0, 0] | [0.8, 0.3] |
| tech | [0, 1, 0, 0] | [-0.5, 0.9] |
| entertainment | [0, 0, 1, 0] | [0.7, 0.2] |
| news | [0, 0, 0, 1] | [-0.3, -0.6] |
Embedding 向量的数值不是随机的,而是通过训练学习出来的。训练过程会让"相似"的类别在向量空间中靠得更近——比如 sports [0.8, 0.3] 和 entertainment [0.7, 0.2] 非常接近。
Embedding 的三大优势
优势 1:维度大幅降低
- One-hot:51,282 条新闻 → 51,282 维向量
- Embedding:51,282 条新闻 → 每条新闻用 64 维向量表示
维度从 5 万降到 64,降低了 800 倍!
优势 2:表达语义相似性
Embedding 向量可以捕捉对象之间的相似性。计算 sports 和 entertainment 的余弦相似度是 0.98(非常相似),而 sports 和 tech 的相似度是 -0.13(不太相似)。这符合我们的直觉!
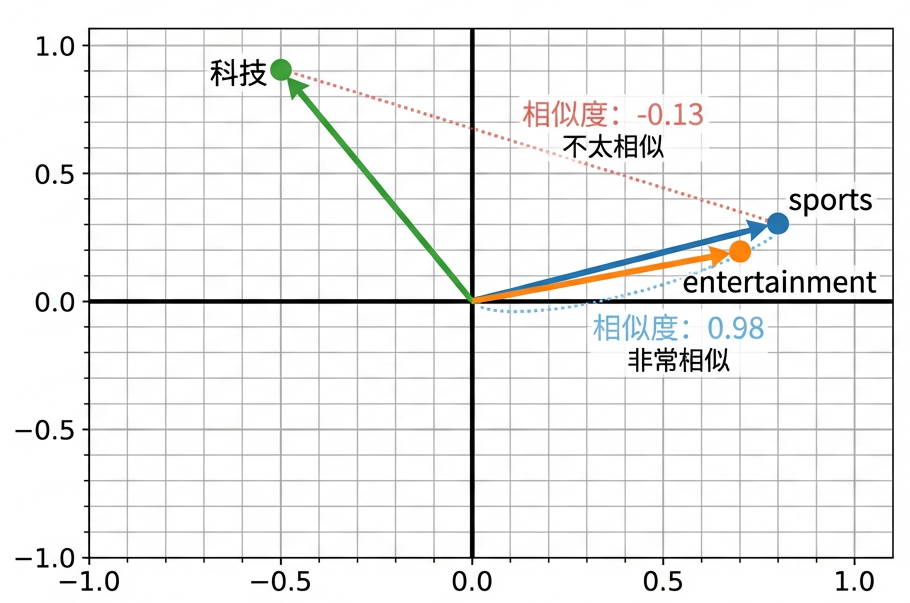 Embedding 向量空间:相似的类别在空间中距离更近
Embedding 向量空间:相似的类别在空间中距离更近
优势 3:泛化能力强
这是 Embedding 最神奇的地方。假设:
- 用户 A 的 Embedding 和用户 C 的 Embedding 很相似(说明他们兴趣相近)
- 用户 C 点击过新闻 B
即使训练集中从未出现"用户 A 点击新闻 B"的样本,模型也能推断:用户 A 可能喜欢新闻 B。这种通过向量相似性进行泛化的能力,是 Embedding 的核心价值——它让模型能够"举一反三"。
Embedding 的工作原理
Embedding 本质上是一个可学习的查找表(Lookup Table)。
想象一本字典:你输入一个单词(ID),字典返回它的解释(向量)。Embedding 就是这样一本"数字字典"——给定一个 ID,返回对应的向量。
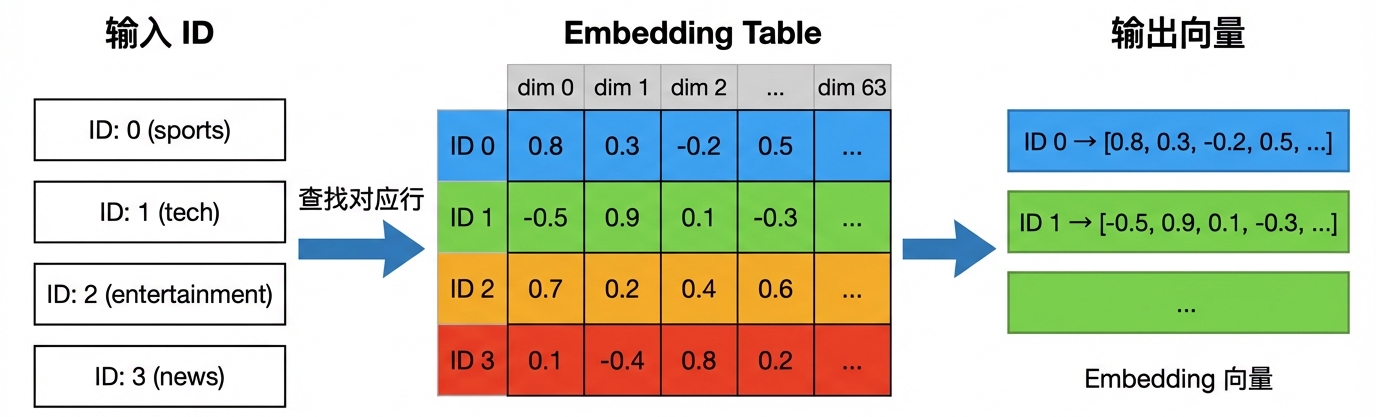 Embedding 查找表:给定 ID,返回对应的向量
Embedding 查找表:给定 ID,返回对应的向量
查找表的概念
假设我们有 4 个新闻类别,想用 2 维 Embedding 表示它们。我们需要一个 4×2 的矩阵:
| ID | 类别 | Embedding 向量 |
|---|---|---|
| 0 | sports | [0.8, 0.3] |
| 1 | tech | [-0.5, 0.9] |
| 2 | entertainment | [0.7, 0.2] |
| 3 | news | [-0.3, -0.6] |
查找类别 1(tech)的 Embedding?直接取矩阵的第 1 行:[-0.5, 0.9]。就这么简单!
PyTorch 中的 Embedding 层
PyTorch 提供了 nn.Embedding 层来实现这个查找表:
import torch.nn as nn
# 创建 Embedding 层:4 个类别,每个用 2 维向量表示
embedding_layer = nn.Embedding(num_embeddings=4, embedding_dim=2)
# 查找类别 1 的 Embedding
category_id = torch.tensor([1])
category_embedding = embedding_layer(category_id) # 输出: tensor([[-0.1234, 0.5678]])两个关键点:
- Embedding 矩阵是随机初始化的,需要通过训练来学习
- Embedding 向量是可学习的参数,会随着训练不断更新
Embedding 如何学习
Embedding 向量不是人工设计的,而是通过训练任务自动学习出来的。
以点击预测为例:模型的输入是用户 ID 和新闻类别 ID,输出是点击概率。训练过程中,模型会根据预测误差调整 Embedding 向量:
- 如果用户 A 和用户 B 的点击行为相似,它们的 Embedding 向量会逐渐靠近
- 如果两个类别经常被同一批用户点击,它们的 Embedding 向量也会靠近
这就像让模型自己"发现"用户和内容之间的隐藏关系。
MIND 数据集实战:用 Embedding 预测点击
理论讲完了,让我们在 MIND 数据集上实践。完整代码见 src/ch03/01_feature_embedding.py,这里只展示核心思路。
整体流程
- 构建 ID 映射:将用户 ID 和新闻类别映射到连续整数(0, 1, 2, ...)
- 构建训练样本:从 behaviors 数据中提取 (用户ID, 类别ID, 是否点击) 三元组
- 定义模型:用户 Embedding + 类别 Embedding → 全连接层 → 点击概率
- 训练模型:用 BCE 损失函数优化 Embedding 向量
模型结构
模型结构非常简单:
class EmbeddingClickModel(nn.Module):
def __init__(self, num_users, num_categories, embedding_dim=32):
super().__init__()
self.user_embedding = nn.Embedding(num_users, embedding_dim)
self.category_embedding = nn.Embedding(num_categories, embedding_dim)
self.fc = nn.Sequential(
nn.Linear(embedding_dim * 2, 64),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(64, 1),
nn.Sigmoid()
)
def forward(self, user_ids, category_ids):
user_emb = self.user_embedding(user_ids)
category_emb = self.category_embedding(category_ids)
features = torch.cat([user_emb, category_emb], dim=1)
return self.fc(features).squeeze()核心思路:把用户和类别的 Embedding 拼接起来,通过全连接层预测点击概率。
Embedding 的可视化与分析
训练完成后,我们可以提取学到的 Embedding 向量,分析它们的语义关系。
运行代码后,你会看到类似这样的输出:
类别相似度分析:
sports:
→ lifestyle: 0.8234
→ entertainment: 0.7891
→ travel: 0.6543
finance:
→ news: 0.7123
→ weather: 0.5432
→ sports: -0.2341关键洞察:训练后的 Embedding 能够自动学习到类别之间的语义关系。"sports"与"lifestyle"、"entertainment"相似度较高(都是休闲内容),而与"finance"相似度较低。这些关系不是人工设定的,而是模型从用户点击行为中自动学习到的。
预训练 Embedding:站在巨人的肩膀上
前面我们从零训练 Embedding,但这需要大量数据。在实际应用中,我们通常使用预训练 Embedding——在大规模语料上预先训练好的向量表示。
为什么需要预训练 Embedding
MIND 数据集的训练样本只有 15 万条,这对于学习高质量的文本 Embedding 来说远远不够。但如果我们使用在数十亿文本上预训练的模型(如 BERT),就能获得更好的语义表示。
这就像学英语:你可以从零开始学(从零训练),也可以先学会中文再学英语(预训练迁移)——后者通常更快更好。
使用 BERT 提取新闻标题特征
BERT 是 Google 在 2018 年提出的预训练语言模型,能够理解词语的上下文语义。使用 BERT 提取新闻标题的 Embedding 非常简单:
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
bert_model = BertModel.from_pretrained('bert-base-uncased')
# 提取标题 Embedding
inputs = tokenizer("Trump says he will meet with Putin", return_tensors='pt')
outputs = bert_model(**inputs)
title_embedding = outputs.last_hidden_state[:, 0, :] # [1, 768]预训练 Embedding 的优势:
- 无需训练:直接使用,省时省力
- 语义丰富:能理解"bank"在"river bank"和"bank account"中的不同含义
- 泛化能力强:即使是训练集中没见过的词语,也能给出合理的表示
Embedding 的权重共享
Embedding 层有一个重要特性:权重共享(Weight Sharing)。
回顾我们的 Embedding 层:nn.Embedding(num_users=50000, embedding_dim=32)。这个层内部维护了一个 [50000, 32] 的矩阵。当我们查找用户 ID=100 的 Embedding 时,实际上是在访问矩阵的第 100 行。
关键点:无论用户 100 在模型中出现多少次,它的 Embedding 向量都是同一个——矩阵的第 100 行。这就是"权重共享"。
这种共享机制有两个重要作用:
- 参数效率:50,000 个用户只需要 160 万个参数,而不是为每次出现都存储一个向量
- 学习效率:用户 100 的每次出现都会更新同一个 Embedding 向量,使得学习更加高效
Embedding 的最佳实践
1. Embedding 维度的选择
维度太小,表达能力不足;维度太大,容易过拟合。经验法则:
| 特征类型 | 数量级 | 推荐维度 |
|---|---|---|
| 类别特征(如新闻类别) | 几十个 | 8-32 维 |
| ID 特征(如用户 ID) | 数千个 | 16-32 维 |
| ID 特征(如用户 ID) | 数万个 | 32-64 维 |
| ID 特征(如用户 ID) | 数十万个 | 64-128 维 |
| 文本特征(预训练模型) | - | 使用原始维度(如 BERT 的 768 维) |
2. 初始化策略
PyTorch 的 nn.Embedding 默认使用正态分布初始化。如果有预训练的 Embedding,可以用它来初始化:
model.category_embedding.weight.data.copy_(pretrained_embeddings)3. 是否冻结 Embedding
使用预训练 Embedding 时,可以选择是否在训练时更新它:
model.category_embedding.weight.requires_grad = False # 冻结,不更新
model.category_embedding.weight.requires_grad = True # 解冻,允许微调建议:数据量小(< 10 万样本)时冻结;数据量大(> 100 万样本)时解冻微调。
本章我们深入理解了 Embedding 技术——深度学习推荐系统的基石。从 One-hot 编码的维度灾难,到 Embedding 的降维打击;从随机初始化的查找表,到通过训练学习语义关系;从零训练 Embedding,到使用 BERT 等预训练模型。
核心要点回顾:
One-hot 的两大问题:维度爆炸(百万级参数)和无法表达相似性(所有类别距离相等)
Embedding 的三大优势:维度大幅降低(降低 800 倍)、表达语义相似性、泛化能力强
Embedding 的本质:可学习的查找表,通过训练任务自动学习对象的向量表示
权重共享机制:同一个 ID 的 Embedding 向量在模型中是共享的,提高参数效率和学习效率
预训练 Embedding:使用 BERT 等预训练模型可以获得更好的语义表示,无需大量训练数据
在第二章中,我们用逻辑回归实现了 CTR 预估,但 AUC 只有 0.53。现在有了 Embedding 技术,我们可以用更丰富的特征表示来提升模型效果。但逻辑回归仍然是线性模型,无法捕捉特征之间的复杂交互。
下一步:如何让模型自动学习特征交叉?如何用神经网络捕捉非线性关系?答案就在下一节——DeepFM,一个结合了因子分解机(FM)和深度神经网络(DNN)的强大模型。