协同过滤算法(Numpy 实现)
有了数据,就可以开始写算法了。我们已经完成了 MIND 数据集的探索,构建了用户-新闻交互数据。基于这些数据,用纯 Numpy 从零实现推荐系统最经典的算法——协同过滤(Collaborative Filtering, CF) ,不依赖任何机器学习框架,从零理解"找相似用户、推荐他们喜欢的内容"的核心逻辑。
协同过滤的核心思想非常直观:物以类聚,人以群分。它不需要理解物品的内容(标题、类别),只需要分析用户的行为模式,就能发现"相似的人喜欢相似的东西"。这种思想在 1990 年代被提出后,至今仍是工业界推荐系统的重要基石。
代码说明
本节代码位于 src/ch02/02_cf_numpy.py。运行前请确保:
- 已下载MIND数据集到
src/dataset/train/MINDsmall_train/ - 已安装依赖:
pip install numpy pandas scikit-learn - 在
src/ch02/目录下运行:python 02_cf_numpy.py
协同过滤的起源与哲学
协同过滤的名字来源于"协同"(Collaborative)——多个用户的行为数据被汇聚在一起,共同"协作"完成对每个用户的推荐。这个概念最早可以追溯到 1992 年 Xerox PARC 的 Tapestry 系统,但真正让它名声大噪的是 1994 年 GroupLens 项目对新闻推荐的研究,以及后来 Amazon 对 ItemCF 的大规模应用。
协同过滤背后的哲学假设是:过去行为相似的人,未来也可能有相似的偏好。这个假设在很多场景下都成立——喜欢科幻电影的人往往也喜欢其他科幻电影,喜欢摇滚乐的人可能也会喜欢朋克。这种"行为即兴趣"的思路,让协同过滤可以完全绕开对物品内容的理解,仅凭行为数据就能做出不错的推荐。
协同过滤主要分为两种:UserCF(基于用户的协同过滤) 和 ItemCF(基于物品的协同过滤)。本节将分别实现这两种算法,并进行离线评估。
协同过滤在多级架构中的位置
在第一章中,我们介绍了推荐系统的"召回-粗排-精排-重排"多级架构。协同过滤在工业界通常用于召回层——从百万级物品中快速筛选出数千个候选。由于计算复杂度的限制,我们不可能对所有物品都计算相似度并排序。
本章实现的协同过滤算法是"全量排序"版本——对所有物品计算相似度后排序,这是为了帮助你理解算法的核心原理。在工业实践中,会使用向量检索技术(如Faiss、Annoy)来加速召回过程,这些内容将在后续章节介绍。
UserCF:找到你的"知音"
UserCF 的核心思路可以用一句话概括:找到和你口味相似的人,把他们喜欢而你没看过的东西推荐给你。
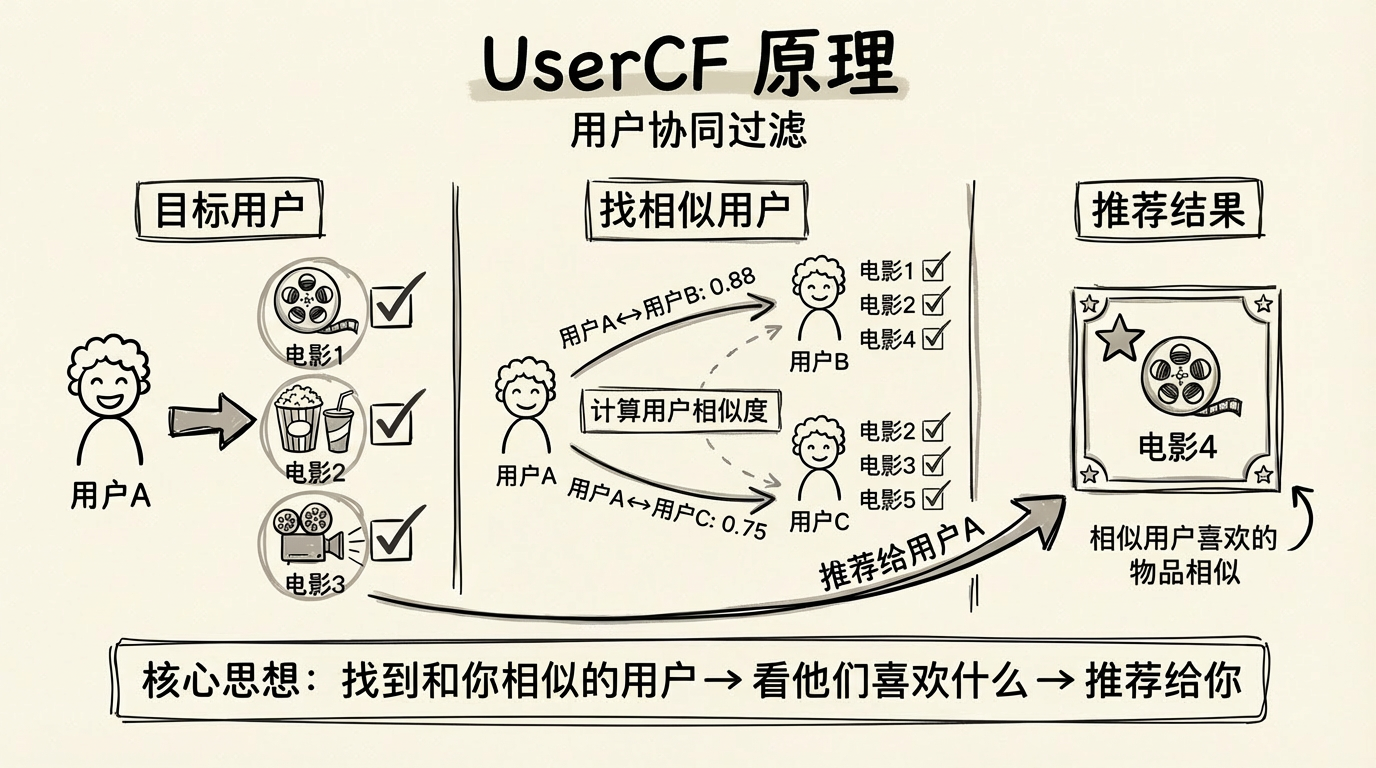 UserCF 原理:先找相似用户,再聚合他们的偏好
UserCF 原理:先找相似用户,再聚合他们的偏好
想象一个场景:你和小明都喜欢科幻电影,你们都看过《星际穿越》《火星救援》《流浪地球》并给了好评。小明还看了《三体》并且很喜欢,而你还没看过。UserCF 的逻辑是:既然你们过去的品味如此相似,小明喜欢的《三体》你大概率也会喜欢。
更形式化地说,UserCF 的推荐过程分为以下步骤:
第一步:计算用户相似度。我们需要量化"两个用户有多相似"。最常用的方法是余弦相似度:把每个用户表示成一个向量(比如用户看过的电影列表),计算两个向量夹角的余弦值。余弦值越接近 1,说明两个用户的"口味向量"方向越一致,即兴趣越相似。
第二步:找到目标用户的 Top-K 相似用户。我们不会参考所有用户的偏好(那样计算量太大,而且弱关联的用户会引入噪声),而是只选取最相似的 K 个用户作为"邻居"。K 是一个超参数,通常取 10-50。
第三步:聚合邻居的偏好。遍历这 K 个邻居喜欢的所有物品,排除目标用户已经看过的,剩下的物品按照"邻居的相似度加权求和"计算分数。一个物品如果被多个高相似度的邻居喜欢,它的分数就会很高。
第四步:按分数排序,返回 Top-N 推荐。分数最高的 N 个物品就是最终的推荐结果。
余弦相似度详解
余弦相似度是协同过滤中最常用的相似度度量方式。给定两个用户
其中
举个例子:假设有 5 部电影 [A, B, C, D, E],用户 Alice 看过 [A, B, C],用户 Bob 看过 [A, B, D],用户 Carol 看过 [D, E]。
- Alice 的向量:[1, 1, 1, 0, 0]
- Bob 的向量:[1, 1, 0, 1, 0]
- Carol 的向量:[0, 0, 0, 1, 1]
Alice 和 Bob 有较高的相似度(0.67),因为他们都看过 A 和 B;而 Alice 和 Carol 完全不相似(0),因为他们没有共同看过的电影。
为什么不用欧氏距离?
你可能会问:为什么用余弦相似度而不是欧氏距离?原因在于推荐场景的特殊性。
欧氏距离衡量的是两点在空间中的"绝对距离"。如果用户 A 看了 100 部电影,用户 B 看了 10 部电影,即使他们的品味完全一致(B 看的 10 部电影 A 都看过且喜欢),欧氏距离也会因为"看片数量"的差异而认为他们不相似。
余弦相似度只看向量的"方向",不看"长度"。无论你看了多少电影,只要我们喜欢的电影类型分布一致,余弦相似度就会很高。这更符合"品味相似"的直觉——一个电影发烧友和一个偶尔看电影的人,可能有着完全相同的品味。
当然,余弦相似度也有其局限性,比如没有考虑评分的绝对值差异。在有显式评分(1-5 分)的场景下,皮尔逊相关系数可能是更好的选择,因为它会减去用户的平均评分,从而消除"打分宽松"或"打分严格"的个人偏差。
ItemCF:发现物品之间的关联
ItemCF 的思路和 UserCF 对称:找到和你喜欢的东西相似的东西,推荐给你。
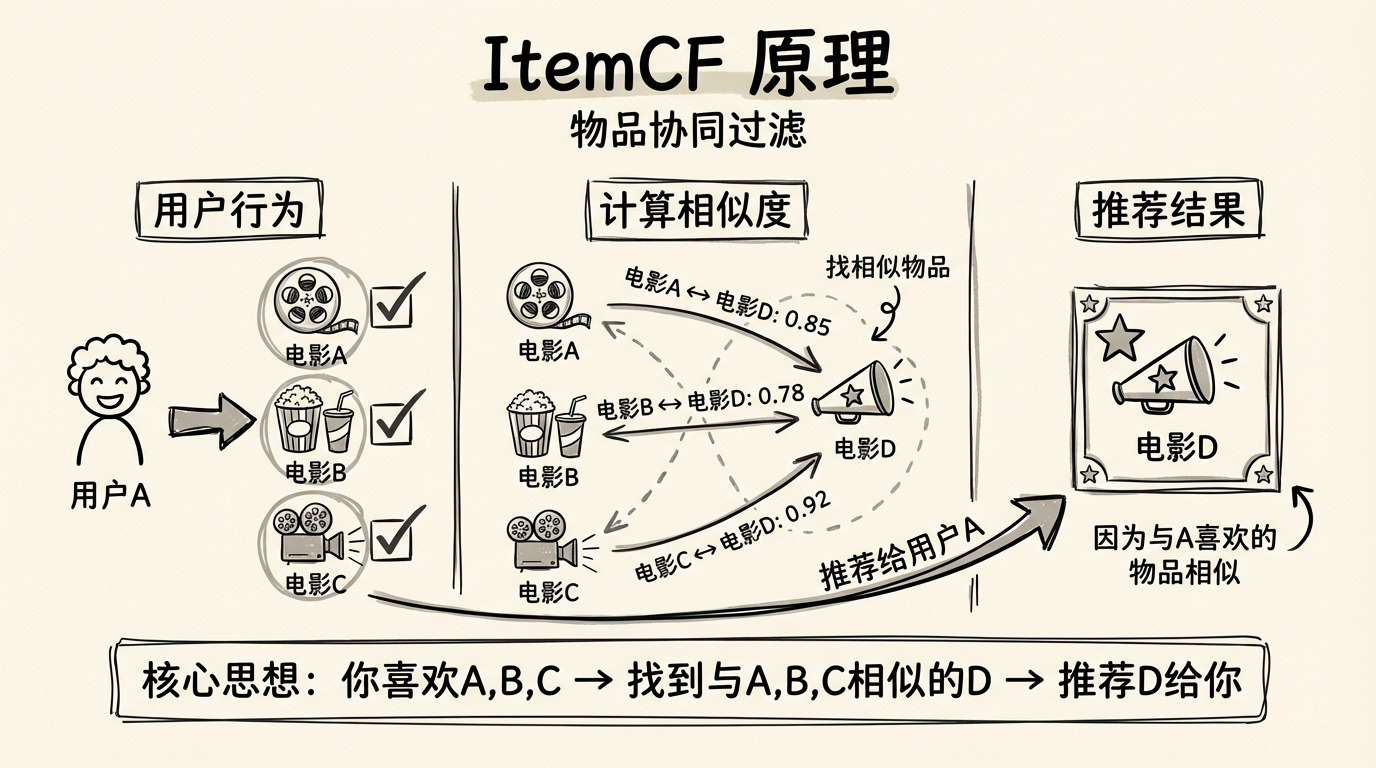 ItemCF 原理:先找物品相似度,再基于用户历史推荐
ItemCF 原理:先找物品相似度,再基于用户历史推荐
继续之前的例子:你喜欢《流浪地球》。系统发现,喜欢《流浪地球》的用户中,有很大比例也喜欢《三体》——这说明这两部作品在用户群体中有很强的关联性,可以认为它们"相似"。于是系统把《三体》推荐给你。
注意这里"相似"的定义:ItemCF 中的物品相似度,不是基于物品内容的相似(比如都是科幻题材),而是基于行为的相似(被同一批用户喜欢)。一本烹饪书和一本园艺书,如果经常被同一批用户购买,在 ItemCF 眼中它们就是"相似"的——这可能反映了某种生活方式偏好。
ItemCF 的推荐步骤:
第一步:计算物品相似度。把每个物品表示成一个向量(喜欢这个物品的用户列表),计算物品之间的余弦相似度。
第二步:对目标用户的每个历史交互物品,找出其相似物品。假设用户看过 10 部电影,我们为每部电影找出最相似的若干部。
第三步:聚合所有相似物品的分数。如果某部电影和用户看过的多部电影都相似,它的聚合分数就会很高。
第四步:排除用户已看过的,返回 Top-N。
UserCF vs ItemCF:计算视角的切换
从数学角度看,UserCF 和 ItemCF 的核心区别只是相似度计算的对象不同:
- UserCF:计算用户相似度矩阵(
) - ItemCF:计算物品相似度矩阵(
)
如果把用户-物品交互表示成矩阵
- UserCF 的相似度基于
的行向量(用户的交互历史) - ItemCF 的相似度基于
的列向量(物品被哪些用户交互过)
这种对称性使得两种算法的实现高度相似,只需要转置一下矩阵即可。
什么时候选 UserCF,什么时候选 ItemCF?
这是一个经典问题,答案取决于场景特点:
| 维度 | UserCF 更适合 | ItemCF 更适合 |
|---|---|---|
| 规模比较 | 物品数 >> 用户数 | 用户数 >> 物品数 |
| 更新频率 | 用户兴趣相对稳定 | 物品关系相对稳定 |
| 时效性 | 物品时效性强(新闻、资讯) | 物品长期有效(电影、商品) |
| 可解释性 | "和你兴趣相似的人也喜欢..." | "喜欢这个的人也喜欢..." |
| 冷启动 | 新物品冷启动更容易 | 新用户冷启动更容易 |
新闻/资讯推荐(如 MIND 数据集)通常选择 UserCF,因为:新闻时效性强,每天都有大量新文章产生,物品(新闻)之间的相似度不稳定;而用户的阅读兴趣模式相对稳定(一个军事爱好者明天还是军事爱好者)。
电商推荐通常选择 ItemCF,Amazon 著名的"购买此商品的用户也购买了..."就是 ItemCF 的直接应用。原因是:商品的关联关系相对稳定(买相机的人往往也买存储卡),而且这种关联有明确的商业价值(可以用于交叉销售)。
视频/音乐推荐往往两者都用,根据具体子场景选择。
相似度计算:更多选择
除了余弦相似度,协同过滤中还有其他几种常用的相似度度量:
皮尔逊相关系数:在余弦相似度的基础上,减去每个用户的平均评分,消除"评分偏置"。适合有显式评分的场景。
Jaccard 相似度:只考虑"是否交互",不考虑交互强度。适合隐式反馈场景。
其中
改进的余弦相似度(IUF):对热门物品做惩罚。如果两个用户都买过可口可乐,这不能说明他们品味相似——因为太多人都买可口可乐了。IUF(Inverse User Frequency)借鉴了 TF-IDF 的思想,对热门物品降权:
其中
数据准备:构建交互矩阵
理论讲完了,让我们开始写代码。协同过滤的输入是一个 用户-物品交互矩阵,矩阵的每个元素表示用户对物品的反馈(1=点击,0=未交互)。
import numpy as np
import pandas as pd
from collections import defaultdict
DATA_DIR = "../dataset/train/MINDsmall_train"
# 加载行为数据
behaviors = pd.read_csv(
f"{DATA_DIR}/behaviors.tsv",
sep="\t",
header=None,
names=["impression_id", "user_id", "time", "history", "impressions"]
)
def build_interactions(behaviors_df, max_rows=20000):
"""从行为日志构建交互数据(只用正样本)"""
user_items = defaultdict(set)
for idx, row in behaviors_df.head(max_rows).iterrows():
user_id = row["user_id"]
# 历史点击
if pd.notna(row["history"]) and row["history"].strip():
for news_id in row["history"].split():
user_items[user_id].add(news_id)
# 当前曝光中的点击
if pd.notna(row["impressions"]):
for item in row["impressions"].split():
news_id, label = item.rsplit("-", 1)
if label == "1":
user_items[user_id].add(news_id)
return user_items
user_items = build_interactions(behaviors)然后构建 ID 映射和交互矩阵:
# 构建 ID 映射
all_users = list(user_items.keys())
all_items = set()
for items in user_items.values():
all_items.update(items)
all_items = list(all_items)
user2idx = {u: i for i, u in enumerate(all_users)}
item2idx = {t: i for i, t in enumerate(all_items)}
idx2user = {i: u for u, i in user2idx.items()}
idx2item = {i: t for t, i in item2idx.items()}
n_users = len(all_users)
n_items = len(all_items)
print(f"用户数: {n_users:,}")
print(f"物品数: {n_items:,}")
# 构建交互矩阵(用户 × 物品)
interaction_matrix = np.zeros((n_users, n_items), dtype=np.float32)
for user, items in user_items.items():
u_idx = user2idx[user]
for item in items:
i_idx = item2idx[item]
interaction_matrix[u_idx, i_idx] = 1.0
print(f"交互矩阵形状: {interaction_matrix.shape}")
print(f"稀疏度: {1 - interaction_matrix.sum() / (n_users * n_items):.4%}")用户数: 15,427
物品数: 27,897
交互矩阵形状: (15427, 27897)
稀疏度: 99.8985%交互矩阵非常稀疏(99.9% 的元素是 0),这是推荐系统的典型特点——用户只会和极少数物品产生交互。这种稀疏性既是挑战(数据不足,难以计算准确的相似度),也是机会(有大量物品可以推荐)。
关于稀疏度
99.9% 的稀疏度意味着平均每个用户只与 0.1% 的物品有交互。在 27,897 个物品中,每个用户平均只点击了约 28 个。这个数字看起来很小,但在新闻场景中是合理的——大多数用户只是快速浏览标题,真正点开阅读的新闻并不多。
UserCF 实现
现在让我们实现 UserCF。核心步骤是计算用户相似度矩阵,然后基于相似用户推荐。
计算用户相似度
def cosine_similarity_matrix(matrix):
"""计算余弦相似度矩阵"""
# 归一化:每行除以其 L2 范数
norms = np.linalg.norm(matrix, axis=1, keepdims=True)
norms[norms == 0] = 1 # 避免除零
normalized = matrix / norms
# 相似度 = 归一化矩阵 × 归一化矩阵的转置
similarity = np.dot(normalized, normalized.T)
return similarity
user_similarity = cosine_similarity_matrix(interaction_matrix)
print(f"用户相似度矩阵形状: {user_similarity.shape}")
# 对角线置零(自己和自己的相似度不参与推荐)
np.fill_diagonal(user_similarity, 0)用户相似度矩阵形状: (15427, 15427)实现 UserCF 推荐函数
def user_cf_recommend(user_idx, interaction_matrix, user_similarity, k=20, n_rec=5):
"""
UserCF 推荐
Args:
user_idx: 目标用户索引
interaction_matrix: 用户-物品交互矩阵
user_similarity: 用户相似度矩阵
k: 使用 top-k 相似用户
n_rec: 推荐物品数量
"""
# 找到 top-k 相似用户
sim_scores = user_similarity[user_idx]
top_k_users = np.argsort(sim_scores)[-k:][::-1]
# 目标用户已交互的物品
user_interacted = set(np.where(interaction_matrix[user_idx] > 0)[0])
# 聚合相似用户的物品偏好
item_scores = defaultdict(float)
for sim_user in top_k_users:
sim = sim_scores[sim_user]
if sim <= 0:
continue
sim_user_items = np.where(interaction_matrix[sim_user] > 0)[0]
for item_idx in sim_user_items:
if item_idx not in user_interacted:
item_scores[item_idx] += sim # 加权聚合
# 按分数排序,返回 top-n
sorted_items = sorted(item_scores.items(), key=lambda x: x[1], reverse=True)
return [item for item, score in sorted_items[:n_rec]]测试 UserCF
# 选择一个用户测试
test_user_idx = 0
test_user_id = idx2user[test_user_idx]
user_history = [idx2item[i] for i in np.where(interaction_matrix[test_user_idx] > 0)[0][:5]]
print(f"目标用户: {test_user_id}")
print(f"历史点击(前5条): {user_history}")
# 找相似用户
sim_scores = user_similarity[test_user_idx]
top_similar_users = np.argsort(sim_scores)[-3:][::-1]
print(f"最相似的3个用户:")
for rank, sim_user_idx in enumerate(top_similar_users, 1):
print(f" {rank}. {idx2user[sim_user_idx]} (相似度: {sim_scores[sim_user_idx]:.4f})")
# 推荐
recommendations = user_cf_recommend(test_user_idx, interaction_matrix, user_similarity, k=20, n_rec=5)
print(f"UserCF 推荐结果:")
for rank, item_idx in enumerate(recommendations, 1):
print(f" {rank}. {idx2item[item_idx]}")目标用户: U13740
历史点击(前5条): ['N19347', 'N63302', 'N55189', 'N45794', 'N55689']
最相似的3个用户:
1. U90052 (相似度: 0.3651)
2. U1745 (相似度: 0.3354)
3. U82868 (相似度: 0.3162)
UserCF 推荐结果:
1. N10059
2. N64273
3. N11116
4. N9719
5. N5902ItemCF 实现
ItemCF 的实现与 UserCF 对称,只需要把交互矩阵转置,计算的就是物品相似度。
计算物品相似度
# 物品相似度 = 交互矩阵转置后计算
item_similarity = cosine_similarity_matrix(interaction_matrix.T)
print(f"物品相似度矩阵形状: {item_similarity.shape}")
np.fill_diagonal(item_similarity, 0)物品相似度矩阵形状: (27897, 27897)实现 ItemCF 推荐函数
def item_cf_recommend(user_idx, interaction_matrix, item_similarity, n_rec=5):
"""
ItemCF 推荐
"""
# 用户已交互的物品
user_interacted = np.where(interaction_matrix[user_idx] > 0)[0]
user_interacted_set = set(user_interacted)
# 聚合已交互物品的相似物品
item_scores = defaultdict(float)
for item_idx in user_interacted:
sim_scores = item_similarity[item_idx]
similar_items = np.argsort(sim_scores)[-50:][::-1]
for sim_item in similar_items:
if sim_item not in user_interacted_set:
item_scores[sim_item] += sim_scores[sim_item]
# 按分数排序
sorted_items = sorted(item_scores.items(), key=lambda x: x[1], reverse=True)
return [item for item, score in sorted_items[:n_rec]]测试 ItemCF
print(f"目标用户: {test_user_id}")
# 展示一个物品的相似物品
sample_item_idx = np.where(interaction_matrix[test_user_idx] > 0)[0][0]
sample_item_id = idx2item[sample_item_idx]
sim_scores = item_similarity[sample_item_idx]
top_similar_items = np.argsort(sim_scores)[-3:][::-1]
print(f"物品 {sample_item_id} 的相似物品:")
for rank, sim_item_idx in enumerate(top_similar_items, 1):
print(f" {rank}. {idx2item[sim_item_idx]} (相似度: {sim_scores[sim_item_idx]:.4f})")
# 推荐
recommendations = item_cf_recommend(test_user_idx, interaction_matrix, item_similarity, n_rec=5)
print(f"ItemCF 推荐结果:")
for rank, item_idx in enumerate(recommendations, 1):
print(f" {rank}. {idx2item[item_idx]}")目标用户: U13740
物品 N19347 的相似物品:
1. N25577 (相似度: 0.1232)
2. N6233 (相似度: 0.1145)
3. N52589 (相似度: 0.1129)
ItemCF 推荐结果:
1. N306
2. N29177
3. N871
4. N16715
5. N51706离线评估
我们使用 留一法(Leave-One-Out) 进行评估:对每个用户,随机隐藏一个正样本作为测试,用剩余数据做推荐,看能否命中这个隐藏的物品。
评估简化说明
下面的评估代码存在一个有意识的简化:相似度矩阵是基于包含测试物品的完整数据预先计算的,评估时只临时移除了交互矩阵中的测试项,但没有重新计算相似度。这构成了轻微的数据泄露——测试物品的信息通过相似度矩阵间接"泄露"给了推荐过程。
严格做法应该在移除测试物品后重新计算相似度矩阵,但这会让评估速度慢几个数量级。在教程场景下,这种简化对结果的影响很小(因为单个物品对整体相似度矩阵的贡献微乎其微),但在正式的论文实验中,必须避免这种泄露。
def evaluate_cf(recommend_func, interaction_matrix, similarity_matrix,
test_users=500, k_rec=10, is_user_cf=True):
"""评估协同过滤算法"""
hits = 0
total = 0
np.random.seed(42)
test_user_indices = np.random.choice(n_users, min(test_users, n_users), replace=False)
for user_idx in test_user_indices:
user_items_idx = np.where(interaction_matrix[user_idx] > 0)[0]
if len(user_items_idx) < 2:
continue
# 随机选一个作为测试集
test_item = np.random.choice(user_items_idx)
# 临时移除测试物品
original_value = interaction_matrix[user_idx, test_item]
interaction_matrix[user_idx, test_item] = 0
# 获取推荐
if is_user_cf:
recs = recommend_func(user_idx, interaction_matrix, similarity_matrix, k=20, n_rec=k_rec)
else:
recs = recommend_func(user_idx, interaction_matrix, similarity_matrix, n_rec=k_rec)
# 恢复
interaction_matrix[user_idx, test_item] = original_value
if test_item in recs:
hits += 1
total += 1
return hits / total if total > 0 else 0
print("评估 UserCF...")
hr_user = evaluate_cf(user_cf_recommend, interaction_matrix, user_similarity,
test_users=500, k_rec=10, is_user_cf=True)
print(f" HR@10: {hr_user:.4f}")
print("评估 ItemCF...")
hr_item = evaluate_cf(item_cf_recommend, interaction_matrix, item_similarity,
test_users=500, k_rec=10, is_user_cf=False)
print(f" HR@10: {hr_item:.4f}")评估 UserCF...
HR@10: 0.4126
评估 ItemCF...
HR@10: 0.1321在 MIND 数据集上,UserCF 的 HR@10 达到了 41.26%,明显优于 ItemCF 的 13.21%。这验证了我们之前的分析:在新闻推荐场景中,用户的兴趣模式比新闻之间的关联更稳定,因此 UserCF 效果更好。
使用 Surprise 框架
手写 Numpy 版本帮助我们理解原理,但在实际工作中,通常会使用成熟的推荐库。Surprise 是 Python 中最流行的轻量级推荐库,内置了多种协同过滤算法。
from surprise import Dataset, Reader, KNNBasic
from surprise.model_selection import train_test_split
from surprise import accuracy
# 准备数据:将之前构建的 user_items 字典转换为 Surprise 格式
ratings_data = []
for user, items in user_items.items():
for item in items:
ratings_data.append((user, item, 1.0)) # 隐式反馈统一为 1.0
ratings_df = pd.DataFrame(ratings_data, columns=["user_id", "item_id", "rating"])
reader = Reader(rating_scale=(0, 1))
data = Dataset.load_from_df(ratings_df, reader)
trainset, testset = train_test_split(data, test_size=0.2, random_state=42)
# UserCF
sim_options_user = {
"name": "cosine",
"user_based": True,
}
user_cf = KNNBasic(k=20, sim_options=sim_options_user, verbose=False)
user_cf.fit(trainset)
predictions = user_cf.test(testset)
print(f"UserCF RMSE: {accuracy.rmse(predictions, verbose=False):.4f}")
# ItemCF
sim_options_item = {
"name": "cosine",
"user_based": False,
}
item_cf = KNNBasic(k=20, sim_options=sim_options_item, verbose=False)
item_cf.fit(trainset)
predictions = item_cf.test(testset)
print(f"ItemCF RMSE: {accuracy.rmse(predictions, verbose=False):.4f}")Surprise 的优势在于:接口简洁、内置交叉验证、支持多种相似度计算方式(cosine、pearson、MSD 等)、易于调参。如果你只是想快速实验,Surprise 是很好的选择;如果需要深度定制或工业级部署,则需要自己实现或使用更重的框架。
工程实践中的常见陷阱
陷阱一:相似度矩阵的内存爆炸。用户相似度矩阵的大小是
陷阱二:离线评估与线上效果的巨大鸿沟。本节的留一法评估是在静态数据上做的,但线上推荐是动态的——用户的行为会随时间变化,新物品不断涌入。一个常见的错误是:离线 HR@10 很高,上线后效果却很差。原因通常是离线评估没有考虑时间因素(用"未来数据"预测"过去的行为"),或者相似度矩阵更新不及时。
协同过滤的局限性
尽管协同过滤简单有效,但它也有一些固有的局限性:
数据稀疏性问题:当交互数据非常稀疏时,很难找到足够相似的用户或物品。我们的 MIND 数据集稀疏度高达 99.9%,这意味着大部分用户对之间没有任何共同交互,无法计算有意义的相似度。
冷启动问题:对于新用户(没有任何历史行为)或新物品(没有任何用户交互),协同过滤完全无能为力。这在新闻场景尤其严重——每天都有大量新文章发布,但它们刚发布时没有任何交互数据。
无法利用内容信息:协同过滤只看行为,完全忽略了物品的内容特征。一篇关于"人工智能"的新闻和一篇关于"机器学习"的新闻,如果没有用户同时点击过它们,协同过滤就无法发现它们的关联。
流行度偏差:热门物品被更多用户交互,因此更容易出现在推荐结果中。这导致推荐结果倾向于热门内容,不利于长尾物品的曝光。
这些问题催生了后续的改进方法:矩阵分解(通过隐向量缓解稀疏性)、基于内容的推荐(利用物品特征解决冷启动)、深度学习方法(融合多种信息源)。我们将在后续章节中逐一探讨。