矩阵分解:隐向量建模
协同过滤直接计算用户或物品之间的相似度,但稀疏性问题严重制约了效果。当大部分用户只与少量物品交互时,很难找到足够的"共同点"来计算可靠的相似度。矩阵分解(Matrix Factorization, MF) 提供了一种优雅的解决方案:不再直接比较用户或物品,而是学习每个用户和物品的低维隐向量表示,用向量内积来预测用户对物品的偏好。这种方法不仅缓解了稀疏性问题,还为后来的 Embedding 技术奠定了思想基础。
代码说明
本节代码位于 src/ch02/03_matrix_factorization.py。运行前请确保:
- 已下载MIND数据集到
src/dataset/train/MINDsmall_train/ - 已安装依赖:
pip install numpy pandas - 在
src/ch02/目录下运行:python 03_matrix_factorization.py
矩阵分解的历史渊源
矩阵分解在推荐系统中的崛起,离不开一场改变整个领域的竞赛——Netflix Prize。
Netflix Prize:改变推荐系统历史的竞赛
2006 年 10 月,流媒体巨头 Netflix 宣布了一项震动学术界和工业界的挑战:谁能将 Netflix 的电影推荐算法准确率提升 10%,就能获得 100 万美元奖金。这在当时是前所未有的巨额奖金,立刻吸引了全球数千支团队参赛。
Netflix 提供了约 1 亿条用户评分数据(48 万用户对 1.7 万部电影的评分),参赛者需要预测用户对未看电影的评分。评估指标是 RMSE(均方根误差),Netflix 原有系统的 RMSE 是 0.9514,目标是将其降低 10% 到 0.8563。
竞赛持续了近三年。2009 年 9 月,由 BellKor、Pragmatic Theory 和 BigChaos 三支团队组成的 "BellKor's Pragmatic Chaos" 联队以 RMSE 0.8567 的成绩夺冠——仅比目标低 0.0004。有趣的是,另一支团队 "The Ensemble" 也达到了完全相同的分数,但因为提交时间晚了 20 分钟而屈居亚军。
这场竞赛带来了几个深远影响:
矩阵分解成为主流。在竞赛早期,最成功的方法是 Simon Funk(真名 Brandyn Webb)在博客上公开的 SVD 算法,后来被称为 FunkSVD。这个简单而高效的方法迅速被参赛者采纳,成为许多顶尖方案的基础组件。
模型融合(Ensemble)的价值被充分验证。最终获胜方案融合了超过 100 个不同的模型,单个模型的提升空间有限,但组合起来效果显著。这一思想至今仍是工业界的标配。
推荐系统从"信息检索"转向"机器学习"。Netflix Prize 之前,推荐系统更多被视为信息检索的一个分支;之后,它成为机器学习的核心应用领域,吸引了大量 ML 研究者的关注。
为什么叫"矩阵分解"?
协同过滤中,我们有一个稀疏的用户-物品评分矩阵
其中:
是 的用户隐向量矩阵,每行 是用户 的 维隐向量 是 的物品隐向量矩阵,每行 是物品 的 维隐向量 是隐向量维度,通常取 50-200
用户
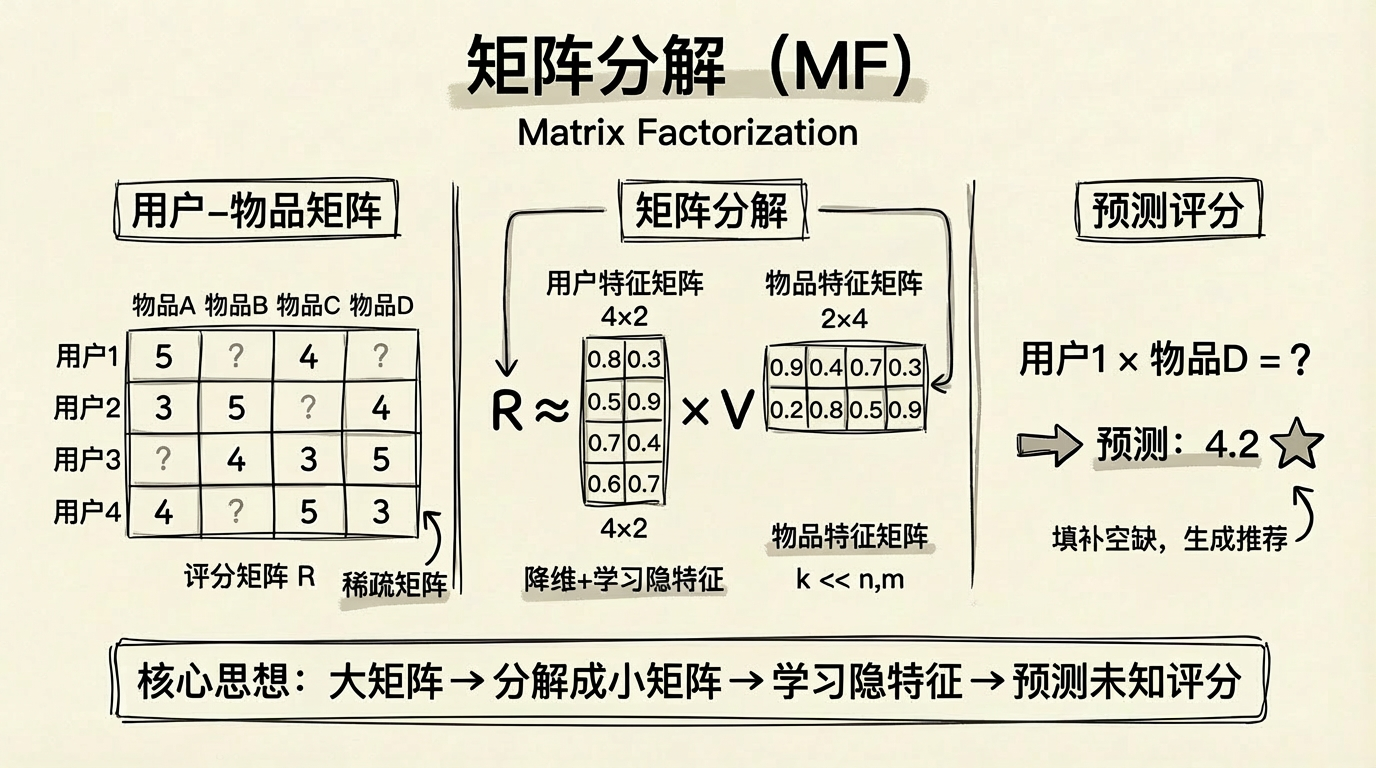 矩阵分解将稀疏的交互矩阵分解为用户和物品的低维隐向量
矩阵分解将稀疏的交互矩阵分解为用户和物品的低维隐向量
隐向量的直观理解
隐向量中的每个维度可以理解为一个隐含特征(latent factor)。以电影推荐为例:
- 第 1 维可能代表"动作片 vs 文艺片"
- 第 2 维可能代表"好莱坞大片 vs 独立电影"
- 第 3 维可能代表"老电影 vs 新电影"
- ...
用户的隐向量表示他在各个维度上的偏好强度,物品的隐向量表示它在各个维度上的特征强度。内积就是"偏好"与"特征"的匹配程度——用户喜欢动作片(用户向量第 1 维为正),电影是动作片(物品向量第 1 维为正),内积贡献为正,预测评分更高。
这些隐含特征是自动学习出来的,不需要人工定义。模型通过拟合观测到的评分数据,自己"发现"了有用的特征维度。这也是矩阵分解被称为"隐语义模型"(Latent Semantic Model)的原因。
FunkSVD:最简单的矩阵分解
FunkSVD 是 Simon Funk 在 Netflix Prize 中提出的方法,因其简洁高效而广受欢迎。它的核心思想是:用梯度下降直接优化隐向量,最小化预测评分与真实评分的误差。
优化目标
给定观测到的评分集合
其中:
- 前半部分是重构误差:预测值与真实值的平方差
- 后半部分是正则化项:防止过拟合,
是正则化系数
随机梯度下降(SGD)
FunkSVD 使用随机梯度下降来优化。对于每个观测到的评分
- 计算预测误差:
- 更新用户隐向量:
- 更新物品隐向量:
其中
梯度推导很直观。以
取负梯度方向更新,就得到了上面的更新公式(省略常数 2)。
Numpy 实现 FunkSVD
import numpy as np
import pandas as pd
from collections import defaultdict
class FunkSVD:
"""
FunkSVD 矩阵分解实现
"""
def __init__(self, n_factors=50, n_epochs=20, lr=0.005, reg=0.02):
"""
Args:
n_factors: 隐向量维度
n_epochs: 迭代轮数
lr: 学习率
reg: 正则化系数
"""
self.n_factors = n_factors
self.n_epochs = n_epochs
self.lr = lr
self.reg = reg
def fit(self, ratings, verbose=True):
"""
训练模型
Args:
ratings: DataFrame,包含 user_id, item_id, rating 三列
"""
# 构建 ID 映射
self.user2idx = {u: i for i, u in enumerate(ratings['user_id'].unique())}
self.item2idx = {t: i for i, t in enumerate(ratings['item_id'].unique())}
self.idx2user = {i: u for u, i in self.user2idx.items()}
self.idx2item = {i: t for t, i in self.item2idx.items()}
self.n_users = len(self.user2idx)
self.n_items = len(self.item2idx)
# 随机初始化隐向量
self.P = np.random.normal(0, 0.1, (self.n_users, self.n_factors))
self.Q = np.random.normal(0, 0.1, (self.n_items, self.n_factors))
# 全局均值(用于预测时的基线)
self.global_mean = ratings['rating'].mean()
# 转换为训练数据
train_data = [
(self.user2idx[row['user_id']],
self.item2idx[row['item_id']],
row['rating'])
for _, row in ratings.iterrows()
]
# SGD 训练
for epoch in range(self.n_epochs):
np.random.shuffle(train_data)
total_loss = 0
for u_idx, i_idx, rating in train_data:
# 预测
pred = self.P[u_idx] @ self.Q[i_idx]
error = rating - pred
# 更新
p_u = self.P[u_idx].copy()
q_i = self.Q[i_idx].copy()
self.P[u_idx] += self.lr * (error * q_i - self.reg * p_u)
self.Q[i_idx] += self.lr * (error * p_u - self.reg * q_i)
total_loss += error ** 2 + self.reg * (np.sum(p_u**2) + np.sum(q_i**2))
if verbose and (epoch + 1) % 5 == 0:
rmse = np.sqrt(total_loss / len(train_data))
print(f"Epoch {epoch + 1}/{self.n_epochs}, RMSE: {rmse:.4f}")
return self
def predict(self, user_id, item_id):
"""预测单个评分"""
if user_id not in self.user2idx or item_id not in self.item2idx:
return self.global_mean
u_idx = self.user2idx[user_id]
i_idx = self.item2idx[item_id]
return self.P[u_idx] @ self.Q[i_idx]
def recommend(self, user_id, n_rec=5, exclude_known=True, known_items=None):
"""
为用户推荐物品
Args:
user_id: 用户 ID
n_rec: 推荐数量
exclude_known: 是否排除已交互物品
known_items: 已知交互物品列表
"""
if user_id not in self.user2idx:
return []
u_idx = self.user2idx[user_id]
# 计算所有物品的预测分数
scores = self.P[u_idx] @ self.Q.T
# 排除已知物品
if exclude_known and known_items:
for item in known_items:
if item in self.item2idx:
scores[self.item2idx[item]] = -np.inf
# 返回 Top-N
top_items_idx = np.argsort(scores)[-n_rec:][::-1]
return [self.idx2item[idx] for idx in top_items_idx]在 MIND 数据上测试
# 准备数据
DATA_DIR = "../dataset/train/MINDsmall_train"
behaviors = pd.read_csv(
f"{DATA_DIR}/behaviors.tsv",
sep="\t",
header=None,
names=["impression_id", "user_id", "time", "history", "impressions"]
)
# 构建评分数据(点击=1,这里我们用隐式反馈)
ratings_data = []
seen = set()
for idx, row in behaviors.head(20000).iterrows():
user_id = row["user_id"]
if pd.notna(row["history"]) and row["history"].strip():
for news_id in row["history"].split():
key = (user_id, news_id)
if key not in seen:
ratings_data.append({"user_id": user_id, "item_id": news_id, "rating": 1.0})
seen.add(key)
if pd.notna(row["impressions"]):
for item in row["impressions"].split():
news_id, label = item.rsplit("-", 1)
if label == "1":
key = (user_id, news_id)
if key not in seen:
ratings_data.append({"user_id": user_id, "item_id": news_id, "rating": 1.0})
seen.add(key)
ratings_df = pd.DataFrame(ratings_data)
print(f"评分数据: {len(ratings_df):,} 条")
print(f"用户数: {ratings_df['user_id'].nunique():,}")
print(f"物品数: {ratings_df['item_id'].nunique():,}")评分数据: 436,652 条
用户数: 15,427
物品数: 27,897# 训练 FunkSVD
model = FunkSVD(n_factors=64, n_epochs=20, lr=0.01, reg=0.01)
model.fit(ratings_df)Epoch 5/20, RMSE: 0.8261
Epoch 10/20, RMSE: 0.4706
Epoch 15/20, RMSE: 0.3448
Epoch 20/20, RMSE: 0.2855# 推荐示例
test_user = ratings_df['user_id'].iloc[0]
user_history = ratings_df[ratings_df['user_id'] == test_user]['item_id'].tolist()
print(f"用户: {test_user}")
print(f"历史交互数: {len(user_history)}")
print(f"历史交互(前5条): {user_history[:5]}")
recommendations = model.recommend(test_user, n_rec=5, known_items=user_history)
print(f"FunkSVD 推荐: {recommendations}")用户: U13740
历史交互数: 10
历史交互(前5条): ['N55189', 'N42782', 'N34694', 'N45794', 'N18445']
FunkSVD 推荐: ['N35729', 'N20304', 'N21019', 'N37033', 'N52314']评估 FunkSVD
def evaluate_mf(model, ratings_df, test_users=500, k_rec=10):
"""评估矩阵分解模型"""
np.random.seed(42)
# 按用户分组
user_items = ratings_df.groupby('user_id')['item_id'].apply(list).to_dict()
# 筛选有足够交互的用户
valid_users = [u for u, items in user_items.items() if len(items) >= 2]
test_user_ids = np.random.choice(valid_users, min(test_users, len(valid_users)), replace=False)
hits = 0
total = 0
for user_id in test_user_ids:
items = user_items[user_id]
# 留一个作为测试
test_item = np.random.choice(items)
train_items = [i for i in items if i != test_item]
# 推荐
recs = model.recommend(user_id, n_rec=k_rec, known_items=train_items)
if test_item in recs:
hits += 1
total += 1
return hits / total
hr = evaluate_mf(model, ratings_df, test_users=500, k_rec=10)
print(f"FunkSVD HR@10: {hr:.4f}")FunkSVD HR@10: 0.0520FunkSVD 的 HR@10 仅为 5.2%,远低于 UserCF 的 41.26%。这个结果看起来"很差",但背后有深刻的原因:
FunkSVD 是为显式评分设计的。Netflix Prize 的场景是预测用户对电影的 1-5 分评分,FunkSVD 学习的是"评分高低"的规律。但 MIND 数据集是隐式反馈(点击/不点击),所有正样本的 rating 都是 1,模型很难区分"非常喜欢"和"有点喜欢"。
隐式反馈需要特殊处理。在只有点击数据的场景下,更合适的方法是使用 BPR(学习相对偏好排序)或 Weighted ALS(给负样本加权)。这些方法的核心思想是:不预测绝对评分,而是学习"用户点击的物品应该排在未点击的物品前面"。我们将在后面的"隐式反馈的矩阵分解"一节中介绍这些方法的原理。
| 方法 | HR@10 | 适用场景 |
|---|---|---|
| FunkSVD | 5.20% | 显式评分(电影评分、商品评价) |
| UserCF | 41.26% | 时效性强的场景(新闻、资讯) |
提示
矩阵分解在 MIND 数据集上的表现远不及 UserCF,这不是矩阵分解本身的问题,而是场景特点决定的:新闻推荐中物品时效性极强,基于邻域的方法能直接利用"最近的相似用户点了什么"这种即时信号,而矩阵分解学到的是更泛化但也更"迟钝"的隐向量表示。在电影、电商等物品生命周期较长的场景中,矩阵分解通常表现更好。矩阵分解的价值不在于它在所有场景都最优,而在于它引入的"隐向量"思想——这是后续 Embedding 和深度学习方法的思想源头。
BiasSVD:引入偏置项
FunkSVD 假设评分完全由用户和物品的隐向量决定,但实际中存在明显的偏置:
- 全局偏置:所有评分的平均值(如豆瓣电影普遍 7 分以上)
- 用户偏置:有些用户倾向于打高分,有些倾向于打低分
- 物品偏置:热门电影普遍评分更高
BiasSVD 将这些偏置显式建模:
其中:
:全局均值 :用户 的偏置 :物品 的偏置
Numpy 实现 BiasSVD
class BiasSVD:
"""
BiasSVD:带偏置项的矩阵分解
"""
def __init__(self, n_factors=50, n_epochs=20, lr=0.005, reg=0.02):
self.n_factors = n_factors
self.n_epochs = n_epochs
self.lr = lr
self.reg = reg
def fit(self, ratings, verbose=True):
# 构建映射
self.user2idx = {u: i for i, u in enumerate(ratings['user_id'].unique())}
self.item2idx = {t: i for i, t in enumerate(ratings['item_id'].unique())}
self.idx2user = {i: u for u, i in self.user2idx.items()}
self.idx2item = {i: t for t, i in self.item2idx.items()}
self.n_users = len(self.user2idx)
self.n_items = len(self.item2idx)
# 初始化参数
self.global_mean = ratings['rating'].mean()
self.bu = np.zeros(self.n_users) # 用户偏置
self.bi = np.zeros(self.n_items) # 物品偏置
self.P = np.random.normal(0, 0.1, (self.n_users, self.n_factors))
self.Q = np.random.normal(0, 0.1, (self.n_items, self.n_factors))
train_data = [
(self.user2idx[row['user_id']],
self.item2idx[row['item_id']],
row['rating'])
for _, row in ratings.iterrows()
]
for epoch in range(self.n_epochs):
np.random.shuffle(train_data)
total_loss = 0
for u_idx, i_idx, rating in train_data:
# 预测(包含偏置)
pred = self.global_mean + self.bu[u_idx] + self.bi[i_idx] + self.P[u_idx] @ self.Q[i_idx]
error = rating - pred
# 更新偏置
self.bu[u_idx] += self.lr * (error - self.reg * self.bu[u_idx])
self.bi[i_idx] += self.lr * (error - self.reg * self.bi[i_idx])
# 更新隐向量
p_u = self.P[u_idx].copy()
q_i = self.Q[i_idx].copy()
self.P[u_idx] += self.lr * (error * q_i - self.reg * p_u)
self.Q[i_idx] += self.lr * (error * p_u - self.reg * q_i)
total_loss += error ** 2
if verbose and (epoch + 1) % 5 == 0:
rmse = np.sqrt(total_loss / len(train_data))
print(f"Epoch {epoch + 1}/{self.n_epochs}, RMSE: {rmse:.4f}")
return self
def predict(self, user_id, item_id):
if user_id not in self.user2idx:
u_bias = 0
p_u = np.zeros(self.n_factors)
else:
u_idx = self.user2idx[user_id]
u_bias = self.bu[u_idx]
p_u = self.P[u_idx]
if item_id not in self.item2idx:
i_bias = 0
q_i = np.zeros(self.n_factors)
else:
i_idx = self.item2idx[item_id]
i_bias = self.bi[i_idx]
q_i = self.Q[i_idx]
return self.global_mean + u_bias + i_bias + p_u @ q_i
def recommend(self, user_id, n_rec=5, exclude_known=True, known_items=None):
if user_id not in self.user2idx:
return []
u_idx = self.user2idx[user_id]
# 计算所有物品的预测分数
scores = self.global_mean + self.bu[u_idx] + self.bi + self.P[u_idx] @ self.Q.T
if exclude_known and known_items:
for item in known_items:
if item in self.item2idx:
scores[self.item2idx[item]] = -np.inf
top_items_idx = np.argsort(scores)[-n_rec:][::-1]
return [self.idx2item[idx] for idx in top_items_idx]SVD++:融合隐式反馈
在显式评分场景中,用户不仅对物品打了分,还隐含地表达了"我看过这个物品"的信息。SVD++ 将这种隐式反馈也纳入模型:
其中:
是用户 交互过的所有物品集合 是物品 的"隐式因子向量",表示"用户看过物品 "这一行为对用户表示的影响
这个公式的含义是:用户的兴趣不仅由其隐向量
SVD++ 在 Netflix Prize 中表现优异,是获胜方案的核心组件之一。但它的计算复杂度较高(每次预测需要遍历用户的所有历史),在大规模场景下不太实用。
ALS:交替最小二乘
SGD 是逐样本更新,每次只用一个评分数据。ALS(Alternating Least Squares,交替最小二乘) 提供了另一种优化思路:固定一个矩阵,用最小二乘法求解另一个矩阵的最优解。
给定
其中
同理,固定
ALS 的优势:
- 每一步都有闭式解,收敛更稳定
- 易于并行化(可以同时更新所有用户或所有物品)
- 适合隐式反馈(通过引入置信度权重)
Spark MLlib 中的推荐算法就是基于 ALS 实现的,非常适合大规模分布式计算场景。
隐式反馈的矩阵分解
前面的方法都是为显式评分设计的。但在很多场景中(如新闻点击、商品浏览),我们只有隐式反馈——用户点了表示可能喜欢,没点不代表不喜欢(可能只是没看到)。
Weighted ALS (WALS)
对于隐式反馈,一个经典方法是 Weighted ALS(也叫 iALS)。核心思想是:
- 将所有未观测的交互视为负样本,但给予较低的置信度
- 观测到的正样本给予较高的置信度
损失函数变为:
其中
BPR:贝叶斯个性化排序
BPR(Bayesian Personalized Ranking) 从排序的角度解决隐式反馈问题。它不预测绝对评分,而是学习物品之间的相对偏好:用户点击过的物品应该排在未点击的物品前面。
对于用户
其中
BPR 的训练过程是:
- 随机采样三元组
,其中 是正样本, 是负样本 - 计算
并更新参数
这种 pairwise 的训练方式在隐式反馈场景下通常比 pointwise(直接预测评分)效果更好。
工程实践中的常见陷阱
陷阱一:学习率过大导致隐向量发散。矩阵分解的 SGD 训练对学习率非常敏感。如果学习率设得太大(如 0.1),隐向量的值会在几个 epoch 内爆炸到 NaN。一个实用的诊断方法是:监控每个 epoch 的 RMSE/Loss,如果出现突然飙升或 NaN,首先将学习率缩小 10 倍。工业界常用的做法是从 0.001 开始,配合学习率衰减(如每 5 个 epoch 乘以 0.9)。
陷阱二:隐向量维度不是越大越好。直觉上,更高的维度应该能捕捉更多信息。但在数据量有限时,过高的维度会导致严重过拟合——训练 RMSE 持续下降,但测试 RMSE 反而上升。经验法则是:数据量小(< 10 万交互)用 16-32 维,中等(10 万-1000 万)用 64-128 维,大规模(> 1000 万)可以尝试 128-256 维。
矩阵分解的现代意义
虽然深度学习推荐模型已经成为主流,但矩阵分解的思想仍然深刻影响着现代推荐系统:
Embedding 的先驱:矩阵分解中的隐向量,本质上就是 Embedding。Word2Vec、Item2Vec 等方法都是将"共现"关系转化为向量学习问题,这与矩阵分解一脉相承。
双塔模型的基础:现代推荐系统中广泛使用的双塔模型(用户塔 + 物品塔),其结构与矩阵分解高度相似——用户向量和物品向量的内积作为匹配分数。深度学习只是用更复杂的网络替代了简单的 Embedding lookup。
向量检索的前提:矩阵分解将用户和物品都表示为向量后,推荐问题就变成了向量检索问题——在海量物品向量中找到与用户向量最匹配的。这正是 Faiss、Annoy 等向量索引技术的应用场景。
矩阵分解通过学习用户和物品的低维隐向量,优雅地解决了协同过滤的稀疏性问题。但无论是协同过滤还是矩阵分解,它们本质上都在解决"评分预测"问题——预测用户会给物品打几分。而在工业界的实际应用中,我们面临的是一个不同的问题:点击率预估(CTR Prediction)。
想象你打开今日头条,首页展示了 10 条新闻标题。系统不关心你会给每条新闻打 1-5 分,它只关心一件事:你会点哪一条? 这是一个二分类问题——点或不点。矩阵分解的内积输出是一个连续值(预测评分),但我们实际需要的是 0-1 之间的概率(点击概率)。
理解了隐向量的思想后,我们自然会问:如何将这种向量表示用于 CTR 预估?答案就在逻辑回归(Logistic Regression)——推荐系统从"评分预测"走向"点击预测"的桥梁。它不仅能输出概率,还能灵活地引入各种特征(用户画像、物品属性、上下文信息),为后续的深度学习方法奠定基础。下一节,我们将用纯 Numpy 实现逻辑回归,理解 CTR 预估的核心逻辑。