逻辑回归:CTR预估的基石
从协同过滤到矩阵分解,我们一直在解决"评分预测"问题——预测用户会给物品打几分。但在工业界的推荐系统中,更常见的场景是点击率预估(Click-Through Rate Prediction):给定一个用户和一个物品,预测用户点击它的概率。
想象你打开今日头条,首页展示了10条新闻。系统不关心你会给每条新闻打几分,它只关心一件事:你会点哪一条? 这是一个典型的二分类问题——点击(1)或不点击(0)。矩阵分解的输出是一个连续值(预测评分),但我们需要的是0-1之间的概率。如何将向量表示转化为点击概率?答案就是逻辑回归(Logistic Regression, LR)。
逻辑回归是推荐系统从"评分预测"走向"点击预测"的关键桥梁。它不仅能输出概率,还能灵活地引入各种特征(用户画像、物品属性、上下文信息),为后续的深度学习方法奠定基础。本节将用纯Numpy实现逻辑回归,理解CTR预估的核心逻辑。
代码说明
本节代码位于 src/ch02/04_logistic_regression.py。运行前请确保:
- 已下载MIND数据集到
src/dataset/train/MINDsmall_train/ - 已安装依赖:
pip install numpy pandas scikit-learn - 在
src/ch02/目录下运行:python 04_logistic_regression.py
从评分预测到点击预测
在深入逻辑回归之前,我们先理解为什么工业界更关注CTR预估而不是评分预测。
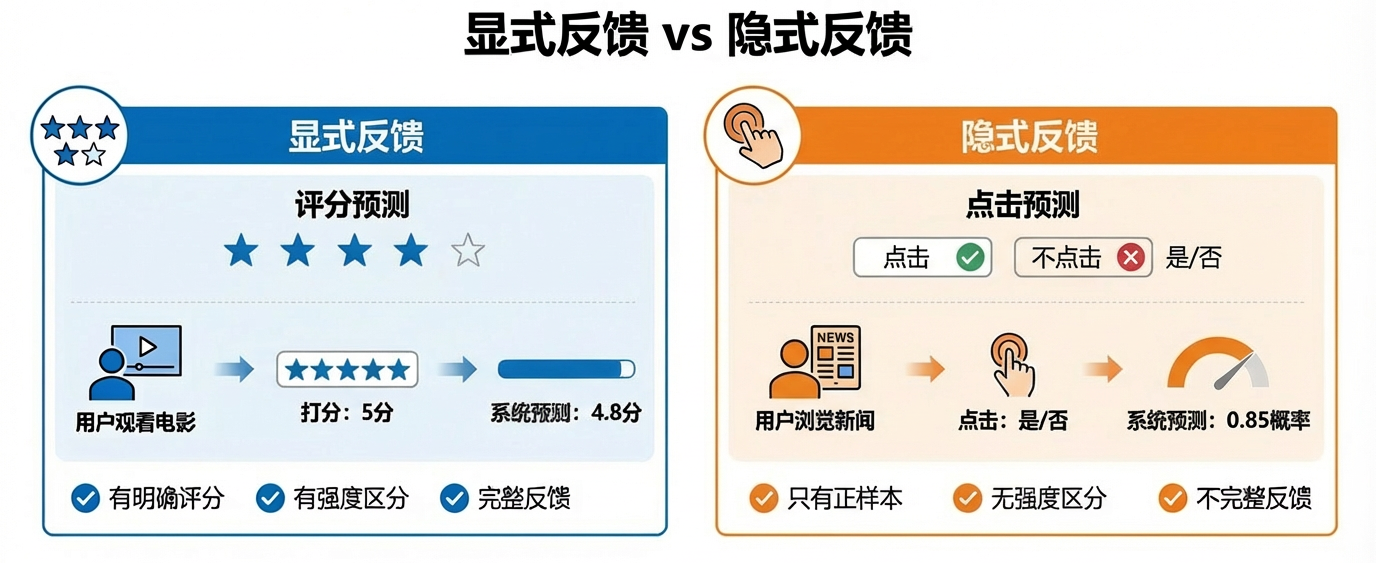
评分预测的场景通常是:用户看过一部电影,给它打了1-5分。系统根据历史评分预测用户会给未看过的电影打几分。这种场景下,我们有显式反馈——用户明确表达了喜好程度。
点击预测的场景更常见:用户浏览新闻列表,点击了其中几条。系统根据点击行为预测用户会点击哪些未看过的新闻。这种场景下,我们只有隐式反馈——用户没有明确评分,只是用"点击"表达了兴趣。
核心区别
| 维度 | 显式反馈 | 隐式反馈 |
|---|---|---|
| 反馈形式 | 评分(1-5) | 点击/浏览 |
| 样本类型 | 正负都有 | 只有正样本 |
| 强度区分 | 有(1-5分) | 无(0-1概率) |
 显式反馈(评分)vs 隐式反馈(点击)
显式反馈(评分)vs 隐式反馈(点击)
隐式反馈有两个特点:
- 只有正样本:用户点击了表示感兴趣,但没点击不代表不感兴趣(可能只是没看到)
- 没有强度区分:点击就是1,不点击就是0,无法区分"非常喜欢"和"有点兴趣"
因此,CTR预估的核心任务是:给定用户特征和物品特征,输出一个0-1之间的概率,表示用户点击的可能性。
逻辑回归的核心思想
逻辑回归虽然名字里有"回归",但它实际上是分类算法。它的核心思想是:用一个线性函数组合各种特征,然后通过Sigmoid函数将结果映射到0-1之间,作为点击概率。
线性组合
假设我们有
其中:
是第 个特征的值 是第 个特征的权重 是偏置项 是线性组合的结果(可以是任意实数)
Sigmoid函数
线性组合
Sigmoid函数的特点是:
- 当
时, - 当
时, - 当
时, - 输出始终在(0, 1)之间
 Sigmoid函数将任意实数映射到0-1之间
Sigmoid函数将任意实数映射到0-1之间
完整的预测公式
将线性组合和Sigmoid结合,得到逻辑回归的预测公式:
这个公式的含义是:给定特征
为什么叫"逻辑"回归?
Sigmoid函数的逆函数是Logit函数:
特征工程:从原始数据到特征向量
逻辑回归的输入是特征向量
核心统计特征
在新闻推荐场景中,我们使用以下6个核心统计特征:
| 特征名 | 含义 | 类型 |
|---|---|---|
news_ctr | 新闻历史点击率 | 连续 |
user_ctr | 用户历史点击率 | 连续 |
category_ctr | 新闻类别点击率 | 连续 |
user_history_len | 用户历史点击数 | 连续 |
hour | 曝光时间(小时) | 连续 |
is_new_user | 是否为新用户 | 二元 |
这些统计特征比简单的One-Hot编码更有信息量,因为它们包含了历史的点击行为模式。
特征选择思路
为什么选择这6个特征?我们的思路是:
- 新闻侧特征:
news_ctr(新闻历史点击率)—— 热门新闻更容易被点击 - 用户侧特征:
user_ctr(用户点击率)、user_history_len(用户活跃度)、is_new_user(是否新用户)—— 不同用户有不同的点击倾向 - 类别侧特征:
category_ctr(类别点击率)—— 某些类别(如体育、娱乐)天然更受欢迎 - 上下文特征:
hour(小时)—— 不同时间段用户活跃度不同
这6个特征覆盖了新闻、用户、类别、上下文四个维度,是CTR预估中最基础也最重要的统计特征。在工业界,还会加入更多复杂特征(如文本Embedding、交叉特征等),但这6个是入门必掌握的核心。
特征穿越(Data Leakage)风险
下面的代码中,news_ctr、user_ctr、category_ctr 等统计特征是基于全量行为数据计算的,包括了时间上晚于当前样本的未来数据。这在严格意义上构成了特征穿越——用"未来的答案"来预测"当前的问题"。
在工业实践中,这是绝对不允许的。正确做法是:只用当前时刻之前的数据来计算统计特征(即"截止到曝光发生前一刻的历史CTR")。本教程为了简化代码逻辑,使用了全量统计,读者需要意识到这一点。特征穿越是推荐系统工程中最常见也最隐蔽的错误之一,它会导致离线指标虚高,上线后效果大幅下降。
构建MIND数据集的特征
让我们从MIND数据集中提取特征,构建训练数据:
本节代码位于 src/ch02/04_logistic_regression.py,以下是核心代码片段:
import numpy as np
import pandas as pd
from collections import defaultdict
DATA_DIR = "../dataset/train/MINDsmall_train"
# 加载数据
behaviors = pd.read_csv(
f"{DATA_DIR}/behaviors.tsv",
sep="\t",
header=None,
names=["impression_id", "user_id", "time", "history", "impressions"]
)
news = pd.read_csv(
f"{DATA_DIR}/news.tsv",
sep="\t",
header=None,
names=["news_id", "category", "subcategory", "title", "abstract",
"url", "title_entities", "abstract_entities"]
)
print(f"行为日志数: {len(behaviors):,}")
print(f"新闻数: {len(news):,}")行为日志数: 156,965
新闻数: 51,282def compute_news_ctr(behaviors_df):
"""计算每篇新闻的历史点击率"""
news_stats = defaultdict(lambda: {"impressions": 0, "clicks": 0})
for _, row in behaviors_df.iterrows():
if pd.notna(row["impressions"]):
for item in row["impressions"].split():
news_id, label = item.rsplit("-", 1)
label = int(label)
news_stats[news_id]["impressions"] += 1
if label == 1:
news_stats[news_id]["clicks"] += 1
news_ctr = {}
for news_id, stats in news_stats.items():
# 加1平滑,避免除零
ctr = (stats["clicks"] + 1) / (stats["impressions"] + 10)
news_ctr[news_id] = ctr
return news_ctr
def compute_user_ctr(behaviors_df):
"""计算用户CTR"""
user_stats = defaultdict(lambda: {"clicks": 0, "impressions": 0, "history_len": 0})
for _, row in behaviors_df.iterrows():
user_id = row["user_id"]
if pd.notna(row["history"]) and row["history"].strip():
user_stats[user_id]["history_len"] = len(row["history"].split())
if pd.notna(row["impressions"]):
for item in row["impressions"].split():
_, label = item.rsplit("-", 1)
label = int(label)
user_stats[user_id]["impressions"] += 1
if label == 1:
user_stats[user_id]["clicks"] += 1
user_ctr = {}
for user_id, stats in user_stats.items():
if stats["impressions"] > 0:
user_ctr[user_id] = (stats["clicks"] + 1) / (stats["impressions"] + 10)
else:
user_ctr[user_id] = 0.05
return user_stats, user_ctr# 计算统计特征
print(" - 计算新闻CTR...")
news_ctr = compute_news_ctr(behaviors)
print(f" - 已计算 {len(news_ctr):,} 篇新闻的CTR")
print(" - 计算用户CTR...")
user_stats, user_ctr = compute_user_ctr(behaviors)
print(f" - 已计算 {len(user_ctr):,} 个用户的CTR") - 计算新闻CTR...
- 已计算 20,288 篇新闻的CTR
- 计算用户CTR...
- 已计算 50,000 个用户的CTRdef extract_features_simple(behaviors_df, news_df, news_ctr, user_stats, user_ctr,
news_category, max_samples=50000):
"""
提取特征 - 使用6个核心统计特征
"""
features = []
labels = []
sample_count = 0
for _, row in behaviors_df.iterrows():
if sample_count >= max_samples:
break
user_id = row["user_id"]
if pd.notna(row["impressions"]):
for item in row["impressions"].split():
news_id, label = item.rsplit("-", 1)
label = int(label)
if news_id not in news_category:
continue
feat = {}
# 核心特征1: 新闻历史CTR
feat["news_ctr"] = news_ctr.get(news_id, 0.05)
# 核心特征2: 用户历史CTR
feat["user_ctr"] = user_ctr.get(user_id, 0.05)
# 核心特征3: 类别CTR
cat_idx = news_category[news_id]
feat["category_ctr"] = category_ctr.get(cat_idx, 0.05)
# 核心特征4: 用户历史长度
feat["user_history_len"] = user_stats[user_id]["history_len"]
# 核心特征5: 小时
time_obj = pd.to_datetime(row["time"])
feat["hour"] = time_obj.hour
# 核心特征6: 是否新用户
feat["is_new_user"] = 1 if user_stats[user_id]["history_len"] == 0 else 0
features.append(feat)
labels.append(label)
sample_count += 1
return features, labels
features, labels = extract_features_simple(
behaviors, news, news_ctr, user_stats, user_ctr,
news_category, max_samples=50000
)
print(f"样本数: {len(features):,}")
print(f"正样本数: {sum(labels):,}")
print(f"负样本数: {len(labels) - sum(labels):,}")
print(f"CTR: {sum(labels)/len(labels):.4f}")样本数: 50,032
正样本数: 1,936
负样本数: 48,096
CTR: 0.0387关键洞察:CTR约为3.87%,这是新闻推荐场景的典型值——大多数曝光的新闻不会被点击。这种极度不平衡的正负样本比例,是CTR预估的主要挑战之一。
Numpy实现逻辑回归
理解了特征和标签,现在用纯Numpy实现逻辑回归的训练和预测。
Sigmoid函数实现
def sigmoid(z):
"""
Sigmoid函数
z: 输入(可以是标量、向量或矩阵)
"""
# 限制z的范围,避免溢出
z = np.clip(z, -500, 500)
return 1 / (1 + np.exp(-z))
# 测试
print(f"sigmoid(0) = {sigmoid(0):.4f}")
print(f"sigmoid(5) = {sigmoid(5):.4f}")
print(f"sigmoid(-5) = {sigmoid(-5):.4f}")sigmoid(0) = 0.5000
sigmoid(5) = 0.9933
sigmoid(-5) = 0.0067特征向量化
将字典形式的特征转换为数值向量:
def vectorize_features_simple(features):
"""
将特征列表转换为矩阵 - 6个核心特征
"""
n_samples = len(features)
n_features = 6
X = np.zeros((n_samples, n_features))
for i, feat in enumerate(features):
X[i, 0] = feat["news_ctr"]
X[i, 1] = feat["user_ctr"]
X[i, 2] = feat["category_ctr"]
X[i, 3] = min(feat["user_history_len"] / 50.0, 1.0)
X[i, 4] = feat["hour"] / 24.0
X[i, 5] = feat["is_new_user"]
return X
X = vectorize_features_simple(features)
y = np.array(labels)
print(f"特征矩阵形状: {X.shape}")
print(f"特征名称: ['news_ctr', 'user_ctr', 'category_ctr', 'user_history_len', 'hour', 'is_new_user']")特征矩阵形状: (50032, 6)
特征名称: ['news_ctr', 'user_ctr', 'category_ctr', 'user_history_len', 'hour', 'is_new_user']逻辑回归类
class LogisticRegression:
"""
逻辑回归实现
"""
def __init__(self, learning_rate=0.01, n_epochs=100, reg_lambda=0.01):
self.lr = learning_rate
self.n_epochs = n_epochs
self.reg_lambda = reg_lambda # 正则化系数
self.weights = None
self.bias = None
def fit(self, X, y, verbose=True):
"""
训练模型(使用梯度下降)
X: (n_samples, n_features)
y: (n_samples,)
"""
n_samples, n_features = X.shape
# 初始化参数
self.weights = np.zeros(n_features)
self.bias = 0
# 梯度下降
for epoch in range(self.n_epochs):
# 前向传播:计算预测概率
z = X @ self.weights + self.bias
y_pred = sigmoid(z)
# 计算损失(带L2正则化的对数损失)
# 防止log(0)溢出
epsilon = 1e-15
y_pred_clip = np.clip(y_pred, epsilon, 1 - epsilon)
loss = -np.mean(y * np.log(y_pred_clip) + (1 - y) * np.log(1 - y_pred_clip))
loss += self.reg_lambda * np.sum(self.weights ** 2) # L2正则化
# 反向传播:计算梯度
dz = y_pred - y # (n_samples,)
dw = (X.T @ dz) / n_samples + 2 * self.reg_lambda * self.weights
db = np.mean(dz)
# 更新参数
self.weights -= self.lr * dw
self.bias -= self.lr * db
if verbose and (epoch + 1) % 10 == 0:
print(f"Epoch {epoch + 1}/{self.n_epochs}, Loss: {loss:.4f}")
return self
def predict_proba(self, X):
"""
预测概率
返回: (n_samples,) 每个样本的点击概率
"""
z = X @ self.weights + self.bias
return sigmoid(z)
def predict(self, X, threshold=0.5):
"""
预测类别(0或1)
"""
proba = self.predict_proba(X)
return (proba >= threshold).astype(int)训练模型
# 划分训练集和测试集(80/20)
np.random.seed(42)
n_samples = len(y)
indices = np.random.permutation(n_samples)
train_size = int(0.8 * n_samples)
train_idx = indices[:train_size]
test_idx = indices[train_size:]
X_train, X_test = X[train_idx], X[test_idx]
y_train, y_test = y[train_idx], y[test_idx]
print(f"训练集: {len(y_train):,} 样本")
print(f"测试集: {len(y_test):,} 样本")
# 训练模型
model = LogisticRegression(learning_rate=1.0, n_epochs=200, reg_lambda=0.01)
model.fit(X_train, y_train)训练集: 40,025 样本
测试集: 10,007 样本
Epoch 10/200, Loss: 0.1998
Epoch 20/200, Loss: 0.1811
Epoch 30/200, Loss: 0.1754
Epoch 40/200, Loss: 0.1722
Epoch 50/200, Loss: 0.1699
Epoch 60/200, Loss: 0.1682
Epoch 70/200, Loss: 0.1669
Epoch 80/200, Loss: 0.1660
Epoch 90/200, Loss: 0.1653
Epoch 100/200, Loss: 0.1648
Epoch 110/200, Loss: 0.1644
Epoch 120/200, Loss: 0.1641
Epoch 130/200, Loss: 0.1639
Epoch 140/200, Loss: 0.1637
Epoch 150/200, Loss: 0.1636
Epoch 160/200, Loss: 0.1635
Epoch 170/200, Loss: 0.1634
Epoch 180/200, Loss: 0.1633
Epoch 190/200, Loss: 0.1633
Epoch 200/200, Loss: 0.1633模型评估
# 在测试集上评估
test_proba = model.predict_proba(X_test)
test_pred = model.predict(X_test)
# 计算指标
from sklearn.metrics import accuracy_score, precision_score, recall_score, roc_auc_score
accuracy = accuracy_score(y_test, test_pred)
precision = precision_score(y_test, test_pred, zero_division=0)
recall = recall_score(y_test, test_pred, zero_division=0)
auc = roc_auc_score(y_test, test_proba)
print(f"测试集指标:")
print(f" Accuracy: {accuracy:.4f}")
print(f" Precision: {precision:.4f}")
print(f" Recall: {recall:.4f}")
print(f" AUC: {auc:.4f}")测试集指标:
Accuracy: 0.9606
Precision: 0.0000
Recall: 0.0000
AUC: 0.5299关键洞察:
- Accuracy很高(96.06%):但这具有欺骗性。因为CTR只有3.87%,即使模型全部预测为"不点击",准确率也能达到96%以上。
- Precision和Recall为0:模型过于保守,几乎不预测正样本。这是因为正负样本极度不平衡,模型倾向于将所有样本预测为负类。
- AUC为0.5299:略高于0.5(随机猜测),说明统计特征比简单的类别特征有一定提升,但效果仍然有限。这提示我们需要更复杂的特征工程或更强大的模型。
为什么AUC只有0.53?
在这个实验中,我们使用了6个统计特征(新闻CTR、用户CTR、类别CTR等),比简单的类别特征有所改进,AUC从0.50提升到了0.53。但这仍然远远不够。在真实场景中,还需要:
用户历史兴趣的细粒度建模:不只是"用户点击率"这种粗粒度统计,而是"用户对哪些类别、哪些主题、哪些实体感兴趣"的细粒度画像。例如,用户可能对"科技-人工智能"感兴趣,但对"科技-硬件评测"不感兴趣。
新闻内容的文本特征:用NLP技术提取标题和摘要的语义信息。例如,用BERT等预训练模型将标题编码为向量,捕捉"这篇新闻讲什么"的深层语义。
更复杂的交叉特征:如"用户喜欢的类别 × 新闻类别"的匹配度、"用户活跃时段 × 新闻发布时间"的匹配度等。这些交叉特征能捕捉更复杂的交互模式。
这也是为什么工业界需要使用深度学习方法来自动学习特征表示——深度模型能自动发现这些复杂的特征组合,而不需要人工设计。
为什么Accuracy会骗人?
在极度不平衡的数据集中(如CTR=4%),Accuracy不是好的评估指标。即使模型把所有样本都预测为负类,准确率也能达到96%。在这种情况下,应该使用AUC、LogLoss或Precision/Recall等指标。
分析特征权重
逻辑回归的一个优势是可解释性强。我们可以查看每个特征的权重,理解哪些因素对点击影响最大:
# 查看特征权重
feature_names = ['news_ctr', 'user_ctr', 'category_ctr', 'user_history_len', 'hour', 'is_new_user']
importance = list(zip(feature_names, model.weights))
importance.sort(key=lambda x: abs(x[1]), reverse=True)
print("特征权重(按绝对值排序):")
for name, weight in importance:
print(f" {name}: {weight:.4f}")特征权重(按绝对值排序):
hour: -0.0760
news_ctr: 0.0654
user_history_len: -0.0420
user_ctr: 0.0305
category_ctr: -0.0029
is_new_user: -0.0028关键洞察:
- hour(小时)权重最大(-0.0760):说明时间对点击率有一定影响,可能是某些时间段用户更活跃
- news_ctr(新闻CTR)权重第二(0.0654):历史点击率高的新闻更容易被点击,这符合直觉
- user_history_len(用户历史长度)权重为负(-0.0420):可能表示历史点击多的用户反而更挑剔
- 其他特征权重较小,说明这些统计特征的区分度有限
消融实验:每个特征到底贡献了多少?
特征权重只能告诉我们方向和相对大小,但无法直接回答"去掉某个特征,模型会变差多少?"这个问题。消融实验(Ablation Study) 是回答这个问题的标准方法:每次去掉一个特征,观察 AUC 的变化。
# 消融实验:逐个去掉特征,观察 AUC 变化
feature_names = ['news_ctr', 'user_ctr', 'category_ctr', 'user_history_len', 'hour', 'is_new_user']
# 基线:使用全部特征
baseline_model = LogisticRegression(learning_rate=1.0, n_epochs=200, reg_lambda=0.01)
baseline_model.fit(X_train, y_train, verbose=False)
baseline_auc = roc_auc_score(y_test, baseline_model.predict_proba(X_test))
print(f"全部特征 AUC: {baseline_auc:.4f}")
print(f"\n去掉单个特征后的 AUC 变化:")
for i, name in enumerate(feature_names):
# 去掉第 i 个特征
X_train_drop = np.delete(X_train, i, axis=1)
X_test_drop = np.delete(X_test, i, axis=1)
drop_model = LogisticRegression(learning_rate=1.0, n_epochs=200, reg_lambda=0.01)
drop_model.fit(X_train_drop, y_train, verbose=False)
drop_auc = roc_auc_score(y_test, drop_model.predict_proba(X_test_drop))
delta = drop_auc - baseline_auc
print(f" 去掉 {name:20s} → AUC: {drop_auc:.4f} (Δ = {delta:+.4f})")全部特征 AUC: 0.5299
去掉单个特征后的 AUC 变化:
去掉 news_ctr → AUC: 0.4977 (Δ = -0.0322)
去掉 user_ctr → AUC: 0.5217 (Δ = -0.0081)
去掉 category_ctr → AUC: 0.5301 (Δ = +0.0002)
去掉 user_history_len → AUC: 0.5702 (Δ = +0.0403)
去掉 hour → AUC: 0.5798 (Δ = +0.0499)
去掉 is_new_user → AUC: 0.5298 (Δ = -0.0001)消融实验揭示了几个重要发现:
- news_ctr 是唯一真正有价值的特征(去掉后 AUC 下降 0.0322)。新闻的历史点击率直接反映了内容的吸引力,是最强的预测信号。
- user_ctr 有微弱贡献(Δ = -0.0081)。用户的整体点击倾向提供了一些信息,但远不如新闻侧特征重要。
- hour 和 user_history_len 去掉后 AUC 反而上升(Δ = +0.0499 和 +0.0403)。这说明这两个特征不仅没有帮助,反而在误导模型——它们引入了噪声,让模型学到了错误的模式。这是一个非常重要的发现:不是所有特征都是有益的,错误的特征会让模型变差。
- category_ctr 和 is_new_user 几乎没有贡献(Δ ≈ 0)。类别粒度太粗,无法区分同一类别下不同新闻的吸引力;新用户标记在样本中占比太小,信息量有限。
这个实验给出了一个比"所有特征都有用"更真实也更有教育意义的结论:特征工程不是"越多越好",而是"越准越好"。hour 和 user_history_len 作为粗粒度的数值特征,与点击行为之间的关系是非线性的(比如中午和晚上点击率高,但不是线性递增),逻辑回归的线性假设无法正确建模这种关系,反而学到了错误的权重。这正是后续 FM 和深度学习方法要解决的问题——自动学习特征的非线性变换和交叉组合。
逻辑回归的局限性与业界实践
局限性
尽管逻辑回归简单有效,但它也有明显的局限性:
无法捕捉特征交叉:逻辑回归假设特征是线性独立的,无法建模"体育新闻在早上更容易被点击"这种交叉效应。要建模这种关系,需要手动构造交叉特征(如"体育_早上"),这在特征维度高时不可行。
表达能力有限:无论有多少特征,逻辑回归的决策边界始终是线性的。对于复杂的非线性关系(如"年龄和兴趣的复杂交互"),逻辑回归难以拟合。
需要大量特征工程:为了让逻辑回归表现好,需要人工设计大量特征(如用户的历史CTR、物品的点击率等)。这些特征工程既耗时又需要领域知识。
逻辑回归在业界的真实地位
看到这里,你可能会想:既然逻辑回归有这么多局限,工业界是不是已经不用它了?恰恰相反,逻辑回归至今仍在工业界广泛应用。
Facebook的广告排序:2014年,Facebook发表论文《Practical Lessons from Predicting Clicks on Ads at Facebook》,揭示了他们的核心方案——GBDT + LR。用梯度提升树(GBDT)自动学习特征交叉,生成新特征,再输入逻辑回归进行最终排序。这种组合既保留了GBDT的非线性能力,又保留了LR的可解释性和高效性。
广告领域的"兜底"模型:在很多广告系统中,逻辑回归是排序层的基础模型。原因有三:
- 可解释性强:每个特征的权重清晰可见,便于排查问题和调试
- 训练速度快:在线学习场景下,可以实时更新模型参数
- 资源消耗低:推理阶段只需一次向量内积,延迟极低
推荐系统的Baseline:即使在使用深度学习的团队中,逻辑回归仍然是必做的Baseline。如果复杂的深度学习模型连LR都打不过,那一定是哪里出了问题。
在线学习场景:逻辑回归的简洁性使其特别适合在线学习(Online Learning)——每来一个样本就更新一次参数。这在需要实时响应用户兴趣变化的场景(如新闻推荐、短视频推荐)中非常重要。
所以,逻辑回归不是"过时的算法",而是工业界的**"瑞士军刀"——简单、可靠、可解释,在合适的场景下依然是一把利器。我们这章实验效果一般(AUC=0.53),不是因为LR本身不行,而是特征还不够丰富**。配上好的特征工程(如GBDT生成的交叉特征),LR依然可以取得很好的效果。
这些局限性催生了更强大的模型:因子分解机(FM)和深度学习方法。FM能自动学习特征交叉,深度学习能捕捉复杂的非线性模式。我们将在下一章深入探讨这些方法。
工程实践中的常见陷阱
陷阱一:特征穿越(Data Leakage)是离线指标虚高的头号元凶。本节已经提到,用全量数据计算 news_ctr 等统计特征会引入未来信息。在工业实践中,这个问题更加隐蔽——比如用"该用户最终是否转化"作为特征去预测"是否点击",或者用包含当前样本的统计值作为特征。诊断方法:如果离线 AUC 异常高(如 > 0.85),先怀疑特征穿越,逐个排查每个特征的时间边界。
陷阱二:用 Accuracy 评估不平衡数据会给你虚假的安全感。本节实验中 Accuracy 高达 96%,但模型实际上什么都没学到(Precision/Recall 均为 0)。在 CTR 预估场景中,正样本通常只占 1%-5%,全部预测为负类就能获得 95%+ 的 Accuracy。正确的做法是:用 AUC 评估排序能力,用 LogLoss 评估概率校准质量,用 Precision@K / Recall@K 评估 Top-K 推荐质量。
陷阱三:正负样本不平衡不能简单地用过采样/欠采样解决。很多教程建议对正样本过采样(如 SMOTE)来平衡数据。但在 CTR 预估中,正负样本比例本身就是重要信息——它反映了真实的点击率水平。如果人为改变比例,模型输出的概率就不再是真实的点击概率,会导致后续的竞价、排序逻辑出错。工业界的做法是:保持原始比例训练,或者使用负采样(Negative Sampling)并在推理时做概率校准。
第二章算法总结与对比
在本章中,我们实现了四个经典推荐算法。下表总结了它们的核心特点、优劣势和适用场景:
| 算法 | 核心思想 | 优势 | 劣势 | 评估结果 | 适用场景 |
|---|---|---|---|---|---|
| UserCF | 找相似用户,推荐他们喜欢的物品 | 简单直观、可解释性强 | 稀疏性问题、用户冷启动 | HR@10: 41.26% | 新闻推荐、社交推荐 |
| ItemCF | 找相似物品,推荐给喜欢类似物品的用户 | 物品关系稳定、易于缓存 | 物品冷启动、多样性不足 | HR@10: 13.21% | 电商推荐、内容推荐 |
| 矩阵分解 | 学习用户和物品的隐向量表示 | 缓解稀疏性、引入隐语义 | 隐式反馈场景效果有限 | HR@10: 5.20% | 评分预测(如电影评分) |
| 逻辑回归 | 线性分类器,输出点击概率 | 快速、可解释、易于在线学习 | 需要特征工程、无法捕捉交叉 | AUC: 0.53 | CTR预估基线、广告排序 |
关键洞察:
- UserCF在新闻场景表现最好(HR@10=41.26%),因为用户兴趣相对稳定,而新闻时效性强
- 矩阵分解效果最差(HR@10=5.20%),因为MIND是隐式反馈数据,矩阵分解在极度稀疏的隐式反馈场景下难以学到有效的隐向量
- 逻辑回归的AUC只有0.53,消融实验进一步揭示了部分特征(hour、user_history_len)反而在误导模型,说明线性模型无法正确建模非线性特征关系
本章我们实现了一个逻辑回归模型,使用6个核心统计特征,AUC达到了0.53。虽然比随机猜测(AUC=0.5)有所提升,但效果仍然有限。面对这样的结果,我们自然会想:如何进一步提升效果?
这个实验揭示了推荐系统的核心挑战:
第一,特征工程的重要性。我们使用了统计特征(CTR、历史长度等),比简单的类别特征有所改进,但远远不够。真实场景中还需要更细粒度的用户兴趣建模、内容文本特征、复杂的特征交叉等。
第二,线性模型的局限性。逻辑回归假设特征之间是线性独立的,无法捕捉复杂的交叉效应。当特征维度高时,手动构造交叉特征变得不可行。
第三,评估指标的选择。Accuracy高达96%却毫无意义,AUC才是更可靠的指标。这教会我们在不平衡数据中如何正确评估模型。
所以这一章的真正目的,不是展示一个效果完美的模型,而是让你亲身体验CTR预估的完整流程,理解为什么简单的线性模型不够,从而为学习更复杂的方法(FM、深度学习)建立认知基础。
矩阵分解让我们理解了隐向量,逻辑回归让我们掌握了CTR预估的框架。但面对复杂的特征交互和非线性关系,我们需要更强大的工具。下一章,我们将进入深度学习方法,看看神经网络如何自动学习特征表示,让推荐系统真正"聪明"起来。